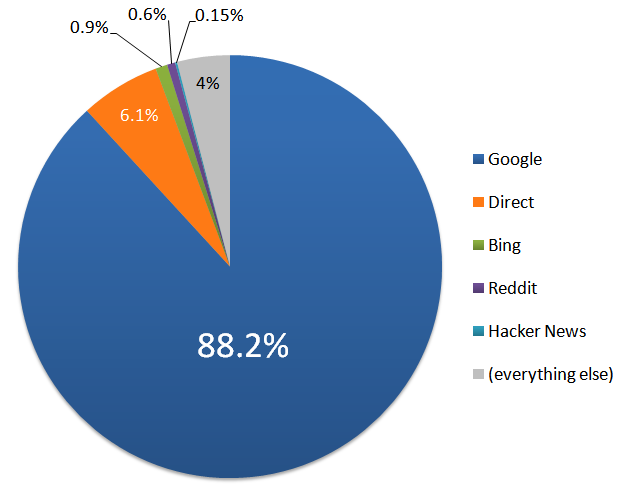
Vamos dar uma olhada no de onde veio o tráfego do stackoverflow.com no ano de 2010.

Quando 88,2% de todo o tráfego do seu site vem de uma única fonte, criticar essa única fonte parece … arriscado. E talvez seja um pouco grosseiro, como olhar um cavalo de presente na boca, ou dizer algo depreciativo em público sobre seu valioso parceiro de negóciostm.
Ainda assim, olhando para as estatísticas, é difícil evitar a conclusão óbvia. Já me disseram muitas vezes que o Google não é um monopólio, mas, aparentemente, eles jogam um na Internet. Os senhores são perfeitamente livres para mudar para qualquer mecanismo de busca alternativo e inviável da Web que desejarem a qualquer momento. Respirem essa doce liberdade, amigos.
Sarcasmo à parte, admiro muito o Google. Meu objetivo não é ser adquirido, porque Estou nessa coisa a longo prazo – mas se eu tivesse para escolher uma empresa para ser adquirida, provavelmente seria o Google. Acho que a ênfase deles no gráfico de informações em detrimento do gráfico social se alinha melhor com a nossa missão do que quase qualquer outro pretendente em potencial que eu possa imaginar. De qualquer forma, desde o início, ficamos muito felizes com o Google como nosso “sugar daddy” do tráfego. Mas, no ano passado, algo estranho aconteceu: os distribuidores de conteúdo começaram a nos superar regularmente no Google em relação ao nosso próprio conteúdo.
A distribuição de nosso conteúdo não é um problema. Na verdade, ela é incentivada. Seria profundamente injusto de nossa parte afirmar a propriedade sobre o conteúdo tão generosamente contribuído para nossos sites e criar um classe baixa de meeiros digitais. Qualquer coisa postada no Stack Overflow, ou em qualquer site da Rede Stack Exchange é licenciado de volta para a comunidade perpetuamente sob a Creative Commons cc-by-sa. A comunidade é proprietária de suas contribuições. Queremos que a o mundo inteiro para ensinar uns aos outros e aprender com as perguntas e respostas publicadas em nossos sites. Remixe, reutilize, compartilhe – e ensine seus colegas! Essa é a nossa missão. É por isso que me levanto de manhã.

Entretanto, implícito nessa estratégia estava o pressuposto de que nós, como fonte canônica das perguntas e respostas originais, sempre estaríamos em primeiro lugar. Considere a Wikipédia – o senhor Quando foi a última vez que o senhor clicou em uma página que nada mais era do que um verbete da Wikipédia legalmente copiado e devidamente atribuído, repleto de anúncios? Nunca, certo? Mas, em teoria, é um modelo de negócios totalmente válido, embora idiota. É por isso que Joel Spolsky e eu estávamos confiantes em compartilhar conteúdo com a comunidade quase sem reservas – porque o Google penaliza impiedosamente os sites que tentam burlar o sistema lucrando injustamente com conteúdo copiado. Remixar e reutilizar é bom, mas produzir cópias baratas em massa com anúncios… não é.
Acho que isso é senso comum, mas também está explicitamente escrito no Diretrizes de conteúdo para webmasters do Google.
No entanto, alguns webmasters tentam melhorar a classificação de suas páginas e atrair visitantes criando páginas com muitas palavras, mas com pouco ou nenhum conteúdo autêntico. O Google tomará medidas contra os domínios que tentam obter uma classificação mais alta exibindo apenas páginas copiadas ou outras páginas geradas automaticamente que não agregam nenhum valor aos usuários. Os exemplos incluem:
Conteúdo raspado. Alguns webmasters fazem uso de conteúdo extraído de outros sites mais confiáveis, partindo do pressuposto de que aumentar o volume de páginas da Web com conteúdo aleatório e irrelevante é uma boa estratégia de longo prazo. O conteúdo puramente extraído, mesmo de fontes de alta qualidade, pode não fornecer nenhum valor agregado aos seus usuários sem serviços úteis adicionais ou conteúdo fornecido pelo seu site. Vale a pena dedicar tempo para criar conteúdo original que diferencie seu site. Isso fará com que seus visitantes retornem e fornecerá resultados de pesquisa úteis.
Em 2010, nossas caixas de correio começaram a transbordar de reclamações dos usuários – reclamações de que eles estavam fazendo pesquisas perfeitamente razoáveis no Google e acabando em sites de scraper que espelhavam o conteúdo do Stack Overflow com anúncios adicionados. Pior ainda, em alguns casos, a pergunta original do Stack Overflow não aparecia em lugar algum nos resultados da pesquisa! Isso é particularmente é estranho porque nossos termos de atribuição exigem links diretos para nós, a fonte canônica da pergunta, sem nofollow. O Google, ao indexar a página extraída, não pode evitar ver que a página extraída tem um link para a fonte canônica. Isso culminou em, entre todas as coisas, um plug-in especial para o navegador que redireciona para o Stack Overflow a partir dos sites fraudulentos. Isso é totalmente deprimente. Joel e eu achávamos que isso era impossível. E senti como se tivesse falhado pessoalmente com todos os senhores.
A ideia de que poderia haver algo errado com o Google era inconcebível para mim. O Google é a gravidade na Web, uma constante onipresente; culpar o Google seria como culpar a gravidade por minha própria falta de jeito. Isso não era nem mesmo uma opção. Comecei com a regra de ouro: a culpa é sempre minha. Fizemos uma grande diligência na webmasters.stackexchange.com para garantir que não estávamos fazendo nada abertamente estúpido, e o uber-mensch Matt Cutts se esforçou para investigar os exemplos de pesquisa verificados manualmente e contribuiu em resposta ao meu tweet solicitando termos de pesquisa em que os scrapers dominavam. Foram encontrados problemas em ambos os lados, e o foram feitas alterações. Sucesso!
Apesar da resolução semi-positiva, fiquei incomodado. Se esses scrapers de lojas de baixo custo estavam se saindo tão bem e gerando tanto tráfego com base em nosso conteúdo, como o restante da Web estava se saindo? Minha fé duradoura na constante gravitacional do Google foi abalada. Abalada até o âmago.
Durante toda a minha investigação, tive dúvidas incômodas de que estávamos vendo sérias rachaduras nos alicerces algorítmicos de busca da casa que o Google construiu. Mas eu tinha medo de escrever um artigo sobre isso, pois temia ser considerado um maluco incompetente. Não me sentia à vontade para compartilhar amplamente essa opinião, pois poderíamos estar fazendo algo obviamente errado. O que costumamos fazer com frequência. A gravidade não pode estar errada. Somos apenas desajeitados… certo?
Não posso deixar de notar que não somos o único site a ter sérios problemas com os resultados de pesquisa do Google nos últimos meses. De fato, a batida do tambor da deterioração da qualidade da pesquisa do Google tem sido praticamente ensurdecedor ultimamente:
De forma anedótica, meus resultados de pesquisa pessoal também têm sido visivelmente piores ultimamente. Como parte das compras de Natal para minha esposa, procurei por “capa para iPhone 4” no Google. Tive que desistir completamente das duas primeiras páginas de resultados de pesquisa por serem totalmente inúteis e, em vez disso, procurei na Amazon.
Todas as pessoas cujas opiniões eu respeito têm expressado o mesmo sentimento. O Google, a ferramenta outrora essencial, está de alguma forma perdendo sua vantagem. Os spammers, os scrapers e as fazendas de conteúdo com SEO de ponta a ponta estão ganhando.
Como qualquer pessoa sã, estou torcendo pelo Google nessa batalha, e não gostaria nada mais do que o Google ajustar alguns botões algorítmicos e tornar todo esse post do blog irrelevante. Ainda assim, essa é a primeira vez desde 2000 que me lembro da qualidade da pesquisa do Google em declínioe isso me inspirou alguns pensamentos um tanto heréticos – será que estamos vendo os primeiros sinais de que a busca algorítmica fracassou como estratégia? Será que a próxima geração de busca está destinada a ser menos algorítmica e mais social?
É uma coisa assustadora até mesmo para se pensar, mas o talvez a gravidade realmente esteja quebrada.