Quando o senhor visita o site da Wikipédia da Wikipedia sobre asfaltoo senhor obtém algumas informações razoavelmente confiáveis sobre asfalto. O que o senhor não obtém, entretanto, é qualquer indicação de quem é o autor. Isso porque o autor é irrelevante. A Wikipédia é um esforço comunitário, resultado de pequenas parcelas de esforço contribuídas por milhões de pessoas em todo o mundo. O foco está no valor das informações agregadas, não em quem são os autores individuais.
Mas quem é essa comunidade? De acordo com Jimmy Wales, a maior parte do trabalho na Wikipédia é feita por uma gangue bem unida de 500:
Wales decidiu realizar um estudo simples para descobrir: ele contou quem fazia mais edições no site. “Eu esperava encontrar algo como a regra 80-20: 80% do trabalho sendo feito por 20% dos usuários, só porque isso parece surgir com frequência. Mas, na verdade, é muito, muito mais rigoroso do que isso: acontece que mais de 50% de todas as edições são feitas por apenas 0,7% dos usuários… 524 pessoas. … E, na verdade, os 2% mais ativos, que são 1.400 pessoas, fizeram 73,4% de todas as edições.” Os 25% restantes das edições, segundo ele, foram feitas por “pessoas que [are] contribuíram com … uma pequena alteração de um fato ou uma pequena correção ortográfica … ou algo assim”.
O Stack Overflow tem alguns aspectos semelhantes aos da wiki, e mesmo minha experiência limitada com o gênero me diz que essa afirmação não é plausível. Aaron Swartz fez seu próprio estudo e chegou a uma conclusão muito diferente:
Escrevi um pequeno programa para analisar cada edição e contar o quanto dela permaneceu na versão mais recente. Em vez de contar as edições, como fez Wales, contei o número de letras com as quais um usuário realmente contribuiu para o artigo atual.
Se o senhor contar apenas as edições, parece que os maiores colaboradores do artigo de Alan Alda (7 dos 10 primeiros) são usuários registrados que (todos, exceto 2) fizeram milhares de edições no site. De fato, o número 4 fez mais de 7.000 edições, enquanto o número 7 fez mais de 25.000. Em outras palavras, se o senhor usar os métodos de Wales, obterá os resultados de Wales: a maior parte do conteúdo parece ter sido escrita por editores pesados.
Mas quando o senhor conta as letras, o quadro muda drasticamente: poucos dos colaboradores (2 dos 10 primeiros) estão sequer registrados e a maioria (6 dos 10 primeiros) fez menos de 25 edições em todo o site. Na verdade, o número 9 fez exatamente uma edição – esta! Com a métrica mais razoável – na verdade, a que o próprio Wales disse que planejava usar na próxima revisão de seu estudo – o resultado se inverte completamente.
Os usuários internos são responsáveis pela grande maioria das edições. Mas são as pessoas de fora que fornecem quase todo o conteúdo.
Satisfazer as necessidades desses dois públicos radicalmente diferentes – os internos e os externos – é a arte do design do wiki. É por isso que, no Stack Overflow, misturamos óleo e água:
- Há um forte senso de autoriacom um sistema de reputação e um bloco de assinatura anexado a cada publicação, como nos blogs e fóruns tradicionais.
- Quando o sistema aprende a confiar em você, é possível editar qualquer coisa – e às vezes mudamos para um modo em que a autoria não é enfatizada para nos concentrarmos no conteúdo resultante, como um wiki.
Não sei se a mistura desses elementos opostos funcionaria em um projeto da escala da Wikipédia. Mas acho que funciona para nós (e quando digo nós, quero dizer, programadores) porque é análogo ao sistema de controle de versão incorporado ao DNA de cada programador. A propriedade comum é muito boa, mas às vezes o senhor ainda precisa saber Quem escreveu essa porcaria. A autoria é importante, a propriedade é importante e, ainda assim, há algo maior, um objetivo maior para o qual todos nós estamos trabalhando, que supera qualquer contribuição individual que possamos fazer. Ambos os elementos estão em jogo.
Ainda assim, absorvemos muita tensão com essa escolha de design, porque autoria e wiki são objetivos fundamentalmente opostos. Como o senhor equilibra o interesse próprio (vote em mim) com o egoísmo (vote neste conteúdo)? Às vezes, isso não funciona. Há uma área irregular nas bordas onde esses dois sistemas se encontram. Por exemplo, considere a pergunta do Stack Overflow intitulada Novas invenções significativas em computação desde 1980.
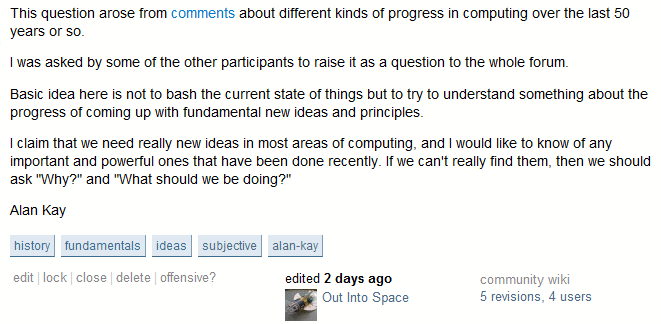
Se o senhor soubesse que essa pergunta era do Alan Kay, cientista da computação ganhador do Prêmio Turing, isso mudaria a maneira como o senhor reagiria a ela? Claro que sim!
Mas o senhor nunca saberia disso, pois nosso bloco de assinatura do wiki só informa isso:
- O último editor (Out Into Space)
- Quantas revisões já foram feitas nesta pergunta até o momento (5)
- Quantos usuários criaram essas revisões (4)
São muitas informações, segundo os padrões típicos de wiki. Quem se importa com quem escreveu a pergunta, desde que seja uma boa pergunta, certo?
Mas isso não funciona totalmente; nós também precisa saber quem é o autor principal, porque essa informação vai colorir e influenciar nossas respostas à pergunta. Reconheço que esse é um exemplo extremo; sem desrespeito aos meus colegas programadores, mas o senhor não ganhou um prêmio Turing. Mesmo em casos mais típicos, a atribuição de autoria importa. Isso nos permite saber com quem estamos falando, qual é seu histórico, quais são suas habilidades e assim por diante. Além disso, como o senhor pode formar uma comunidade quando todos são colaboradores anônimos e aleatórios?
O desafio, portanto, é rastrear a autoria – estritamente para fins informativos – em uma série de revisões de edição. Jimbo errou ao rastrear apenas a contagem de edições. Aaron usou o difflib.SequenceMatcher.find_longest_match para estabelecer a propriedade entre as revisões. Essa é a técnica básica visualizada em Fluxo de histórico da IBM.
Imagine um cenário em que três pessoas farão contribuições para uma página Wiki em momentos diferentes. Cada pessoa edita a página e salva suas alterações no que se torna a versão mais recente da página.
O History Flow conecta o texto que foi mantido igual entre versões consecutivas. As partes do texto que não têm correspondência na versão seguinte (ou anterior) não são conectadas e o usuário vê uma “lacuna” resultante na visualização; isso acontece com as exclusões e inserções.

É muito legal quando aplicado a entradas maiores; veja visualização do fluxo histórico do verbete da Wikipedia sobre evolução.
Agora, a diferenciação de texto, por si só, não é exatamente um problema trivial. Comecei examinando o Distância de Levenshtein, mas esse algoritmo é realmente de força bruta. Veja se o senhor consegue perceber o motivo, nesta visualização da distância de Levenshtein entre “puzzle” e “pzzel”:
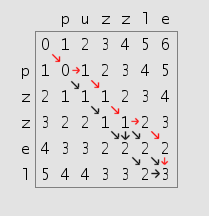
A distância de Levenshtein é uma medida de quantas inserções, exclusões ou substituições são necessárias para transformar a cadeia de caracteres A na cadeia de caracteres B. Quanto maior o número, mais diferentes são as cadeias de caracteres. Estamos comparando duas cadeias de caracteres essencialmente letra por letra, o que significa que o custo típico é O(mn), em que m e n são os comprimentos das duas cadeias de caracteres que estamos comparando. É por isso que o senhor normalmente vê o Levenshtein sendo usado para comparar palavras, nada na ordem de parágrafos ou páginas.
Brinquei com o Levenshtein por um tempo, mas mesmo as implementações otimizadas são brutalmente lentas à medida que o tamanho da entrada aumenta. Percebi rapidamente que um comparação baseada em linhas foi a única viável. Usamos essa Implementação em C# do Um algoritmo de diferença O(ND) e suas variações (pdf).
O que acabei implementando não é nem de longe tão completo quanto o fluxo de histórico da IBM, embora provavelmente seja semelhante à métrica aproximada usada por Aaron. Simplesmente somei o tamanho total de todas as contribuições de linha (inserções ou exclusões) de um determinado autor em uma revisão, com um pequeno multiplicador de bônus de 2x para o autor original. Relatamos a maior porcentagem de autoria na revisão final.
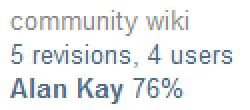
A abordagem de diferença baseada em linha para determinar a autoria está longe de ser perfeita; seria mais precisa se fosse por palavra ou por frase. Mas é uma aproximação razoavelmente boa em meus testes.
E o mais importante, as postagens wiki de Alan Kay parecem ser de Alan Kay.