É provável que o senhor já tenha interagido com grandes modelos de linguagem (LLMs), como os que estão por trás do ChatGPT da OpenAI, e experimentado sua extraordinária capacidade de responder a perguntas, resumir documentos, escrever códigos e muito mais. Embora os LLMs sejam notáveis por si só, com um pouco de conhecimento de programação, o senhor pode aproveitar bibliotecas como LangChain para criar seus próprios chatbots com LLM que podem fazer praticamente qualquer coisa.
Em um ambiente empresarial, uma das formas mais populares de criar um chatbot com LLM é por meio da geração aumentada por recuperação (RAG). Ao projetar um sistema RAG, o senhor usa um modelo de recuperação para recuperar informações relevantes, geralmente de um banco de dados ou corpus, e fornece essas informações recuperadas a um LLM para gerar respostas contextualmente relevantes.
Neste tutorial, o senhor se colocará na pele de um engenheiro de IA que trabalha para um grande sistema hospitalar. O senhor criará um chatbot RAG em LangChain que usa Neo4j para recuperar dados sobre pacientes, experiências de pacientes, localizações de hospitais, visitas, pagadores de seguros e médicos em seu sistema hospitalar.
Clique no link abaixo para fazer o download do código-fonte completo e dos dados desse projeto:
Demonstração: Um chatbot LLM RAG com LangChain e Neo4j
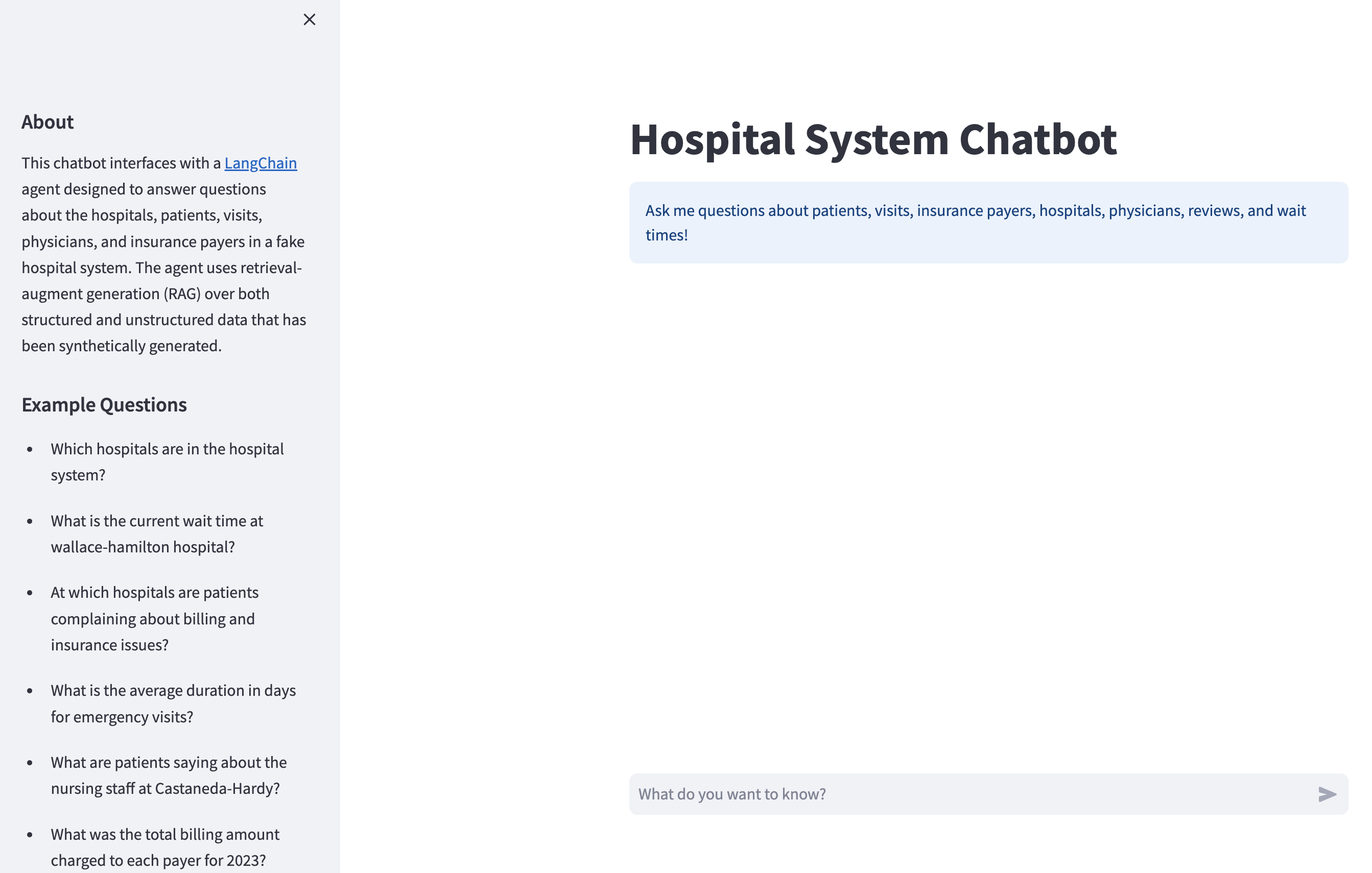
Ao final deste tutorial, o senhor terá um API REST que atende ao seu chatbot LangChain. O senhor também terá uma Streamlit que fornece uma boa interface de bate-papo para interagir com sua API:
Por trás disso, o aplicativo Streamlit envia suas mensagens para a API do chatbot, e o chatbot gera e envia uma resposta de volta para o aplicativo Streamlit, que a exibe para o usuário.
Mais adiante, o senhor terá uma visão geral detalhada dos dados aos quais o chatbot tem acesso, mas se estiver ansioso para testá-lo, poderá fazer perguntas semelhantes aos exemplos apresentados na barra lateral:
O senhor aprenderá a lidar com cada etapa, desde a compreensão dos requisitos e dados comerciais até a criação do aplicativo Streamlit. Há muito a ser desvendado neste tutorial, mas não se sinta sobrecarregado. O senhor obterá informações básicas sobre cada conceito apresentado, juntamente com links para fontes externas que aprofundarão sua compreensão. Agora, é hora de mergulhar de cabeça!
Pré-requisitos
Este tutorial é mais adequado para desenvolvedores Python intermediários que desejam obter experiência prática na criação de chatbots personalizados. Além do conhecimento intermediário de Python, o senhor se beneficiará de uma compreensão de alto nível dos seguintes conceitos e tecnologias:
Nada do que está listado acima é um pré-requisito rígido, portanto, não se preocupe se o senhor não tiver conhecimento de nenhum deles. O senhor será apresentado a cada conceito e tecnologia ao longo do caminho. Além disso, não há melhor maneira de aprender esses pré-requisitos do que implementá-los você mesmo neste tutorial.
A seguir, o senhor terá uma breve visão geral do projeto e começará a aprender sobre o LangChain.
Visão geral do projeto
Ao longo deste tutorial, o senhor criará alguns diretórios que compõem o seu chatbot final. Aqui está um detalhamento de cada diretório:
-
langchain_intro/ajudará você a se familiarizar com o LangChain e a se equipar com as ferramentas necessárias para criar o chatbot que viu na demonstração, e ele não será incluído no seu chatbot final. O senhor abordará esse assunto em Etapa 1. -
data/tem os dados brutos do sistema hospitalar armazenados como arquivos CSV. O senhor explorará esses dados em Etapa 2. Em Etapa 3, o senhor moverá esses dados para um banco de dados Neo4j que o chatbot consultará para responder às perguntas. -
hospital_neo4j_etl/contém um script que carrega os dados brutos dodata/em seu banco de dados Neo4j. É necessário executar esse script antes de criar o chatbot, e você aprenderá tudo o que precisa saber sobre como configurar uma instância do Neo4j em Etapa 3. -
chatbot_api/é o senhor FastAPI que serve ao seu chatbot como um endpoint REST, e é o principal produto deste projeto. Ochatbot_api/src/agents/echatbot_api/src/chains/contêm os objetos LangChain que compõem o seu chatbot. O senhor aprenderá o que são agentes e cadeias mais tarde, mas, por enquanto, saiba que o seu chatbot é, na verdade, um agente LangChain composto de cadeias e funções. -
tests/inclui dois scripts que testam a rapidez com que o seu chatbot pode responder a uma série de perguntas. Isso lhe dará uma ideia de quanto tempo o senhor economiza ao fazer solicitações assíncronas a provedores de LLM como o OpenAI. -
chatbot_frontend/é o seu aplicativo Streamlit que interage com o endpoint do chatbot emchatbot_api/. Essa é a interface do usuário que você viu na demonstração, e você a construirá em Etapa 5.
Todas as variáveis de ambiente necessárias para criar e executar seu chatbot serão armazenadas em um arquivo .env . O senhor implantará o código em hospital_neo4j_etl/, chatbot_api, e chatbot_frontend como contêineres do Docker que serão orquestrados com o Docker Compose. Se quiser experimentar o chatbot antes de passar pelo restante deste tutorial, o senhor pode fazer o download dos materiais e seguir as instruções no arquivo README para colocar tudo em funcionamento:
Com a visão geral do projeto e os pré-requisitos, o senhor está pronto para começar a primeira etapa: familiarizar-se com o LangChain.
Etapa 1: Familiarizar-se com o LangChain
Antes de projetar e desenvolver o seu chatbot, o senhor precisa saber como usar o LangChain. Nesta seção, o senhor conhecerá os principais componentes e recursos do LangChain ao criar uma versão preliminar do chatbot do seu sistema hospitalar. Isso lhe dará todas as ferramentas necessárias para criar o seu chatbot completo.
Use seu editor de código favorito para criar um novo projeto Python e certifique-se de criar um ambiente virtual para suas dependências. Certifique-se de que o Python 3.10 ou posterior esteja instalado. Ative seu ambiente virtual e instale as seguintes bibliotecas:
O senhor também deverá instalar python-dotenv para ajudá-lo a gerenciar as variáveis de ambiente:
O Python-dotenv carrega as variáveis de ambiente do .env para o seu ambiente Python, e isso será útil para o desenvolvimento do seu chatbot. No entanto, você acabará implantando seu chatbot com o Docker, que pode lidar com variáveis de ambiente para você, e não precisará mais do Python-dotenv.
Se ainda não o fez, o senhor precisará baixar reviews.csv dos materiais ou Repositório do GitHub para este tutorial:
Em seguida, abra o diretório do projeto e adicione as seguintes pastas e arquivos:
./
│
├── data/
│ └── reviews.csv
│
├── langchain_intro/
│ ├── chatbot.py
│ ├── create_retriever.py
│ └── tools.py
│
└── .env
A pasta reviews.csv no arquivo data/ é o que o senhor acabou de baixar, e os arquivos restantes que o senhor vê devem estar vazios.
Agora o senhor está pronto para começar a criar seu primeiro chatbot com o LangChain!
Modelos de bate-papo
O senhor já deve ter adivinhado que o componente central do LangChain é o LLM. O LangChain oferece uma interface modular para trabalhar com provedores de LLM, como OpenAI, Cohere, HuggingFace, Anthropic, Together AI e outros. Na maioria dos casos, tudo o que o senhor precisa é de uma chave de API do provedor de LLM para começar a usar o LLM com o LangChain. O LangChain também é compatível com LLMs ou outros modelos de linguagem hospedados em sua própria máquina.
O senhor usará o OpenAI para este tutorial, mas lembre-se de que há muitos provedores excelentes de código aberto e fechado no mercado. O senhor sempre pode testar diferentes provedores e otimizar de acordo com as necessidades do seu aplicativo e as restrições de custo. Antes de prosseguir, verifique se o senhor está inscrito em uma conta da OpenAI e se tem uma conta válida da chave de API válida.
Quando tiver sua chave de API da OpenAI, adicione-a ao seu .env :
Embora o senhor possa interagir diretamente com os objetos LLM no LangChain, uma abstração mais comum é o modelo de bate-papo. Os modelos de bate-papo usam LLMs por trás, mas são projetados para conversas e fazem interface com o mensagens de bate-papo em vez de texto bruto.
Usando mensagens de bate-papo, o senhor fornece ao LLM detalhes adicionais sobre o tipo de mensagem que está enviando. Todas as mensagens têm role e content propriedades. O role informa ao LLM quem está enviando a mensagem, e a propriedade content é a própria mensagem. Aqui estão as mensagens mais comumente usadas:
HumanMessage: Uma mensagem do usuário interagindo com o modelo de linguagem.AIMessage: Uma mensagem do modelo de linguagem.SystemMessage: Uma mensagem que informa ao modelo de linguagem como o senhor deve se comportar. Nem todos os provedores suportam a mensagemSystemMessage.
Existem outros tipos de mensagens, como FunctionMessage e ToolMessagemas o senhor aprenderá mais sobre eles quando construir um agente.
Começar a usar modelos de bate-papo no LangChain é simples. Para instanciar um modelo de bate-papo OpenAI, navegue até langchain_intro e adicione o seguinte código ao chatbot.py:
O senhor primeiro importa dotenv e ChatOpenAI. Então o senhor liga para dotenv.load_dotenv() que lê e armazena variáveis de ambiente do .env. Por padrão, dotenv.load_dotenv() assume .env esteja localizado no diretório de trabalho atual, mas o senhor pode passar o caminho para outros diretórios se .env estiver localizado em outro lugar.
Em seguida, o senhor instancia um ChatOpenAI usando o GPT 3.5 Turbo como LLM de base, e o senhor define temperature para 0. A OpenAI oferece uma diversidade de modelos com preços, recursos e desempenhos variados. O GPT 3.5 turbo é um ótimo modelo para começar, pois tem bom desempenho em muitos casos de uso e é mais barato do que os modelos mais recentes, como o GPT 4 e posteriores.
Observação: É um equívoco comum pensar que a configuração temperature=0 garante respostas determinísticas dos modelos GPT. Embora as respostas estejam mais próximas do determinismo quando temperature=0, não há garantia que o senhor obterá a mesma resposta para solicitações idênticas. Por esse motivo, os modelos GPT podem gerar resultados ligeiramente diferentes dos que o senhor vê nos exemplos deste tutorial.
Para usar o chat_model, abra o diretório do projeto, inicie um interpretador Python e execute o seguinte código:
Nesse bloco, o senhor importa HumanMessage e SystemMessagebem como seu modelo de bate-papo. Em seguida, o senhor define uma lista com um SystemMessage e um HumanMessage e os execute através do chat_model com chat_model.invoke(). Sob o capô, chat_model faz uma solicitação a um endpoint da OpenAI que serve gpt-3.5-turbo-0125e os resultados são retornados como um AIMessage.
Nota: O senhor pode achar que copiar e colar o código de várias linhas deste tutorial em seu REPL padrão do Python é um pouco complicado. Para ter uma experiência melhor, o senhor pode instalar um REPL Python alternativo, como o IPython, bpython ou ptpythonem seu ambiente virtual e execute as interações do REPL com eles.
Como o senhor pode ver, o modelo de bate-papo respondeu O que é Medicaid managed care? fornecido no HumanMessage. O senhor deve estar se perguntando o que o modelo de chat fez com o SystemMessage nesse contexto. Observe o que acontece quando o senhor faz a seguinte pergunta:
Conforme descrito anteriormente, o SystemMessage informa ao modelo como ele deve se comportar. Nesse caso, o senhor disse ao modelo para responder somente a perguntas relacionadas à saúde. É por isso que ele se recusa a dizer ao senhor como trocar o pneu. A capacidade de controlar como um LLM se relaciona com o usuário por meio de instruções de texto é poderosa, e essa é a base para a criação de chatbots personalizados por meio de engenharia de prontidão.
Embora as mensagens de bate-papo sejam uma boa abstração e sejam boas para garantir que o senhor esteja fornecendo ao LLM o tipo certo de mensagem, também é possível passar strings brutas para os modelos de bate-papo:
Nesse bloco de código, o senhor passa a string O que é pressão arterial? diretamente para chat_model.invoke(). Se o senhor quiser controlar o comportamento do LLM sem um SystemMessage aqui, o senhor poderá incluir instruções na entrada da string.
Observação: Nesses exemplos, o senhor usou .invoke(), mas a LangChain tem outros métodos que interagem com LLMs. Por exemplo, .stream() retorna a resposta um token por vez, e o .batch() aceita uma lista de mensagens às quais o LLM responde em uma única chamada.
Cada método também tem um método assíncrono análogo. Por exemplo, o senhor pode executar .invoke() de forma assíncrona com ainvoke().
A seguir, você aprenderá uma maneira modular de orientar a resposta do seu modelo, como fez com o SystemMessage, facilitando a personalização do seu chatbot.
Modelos de prompts
O LangChain permite que o senhor crie prompts modulares para seu chatbot com modelos de prompts. Citando a documentação do LangChain, o senhor pode pensar nos modelos de prompt como receitas predefinidas para gerar prompts para modelos de linguagem.
Suponha que o senhor queira criar um chatbot que responda a perguntas sobre as experiências dos pacientes a partir de suas avaliações. Veja como seria um modelo de prompt para isso:
Primeiro, o senhor importa ChatPromptTemplate e define review_template_strque contém as instruções que o senhor passará para o modelo, juntamente com as variáveis context e question em campos de substituição que a LangChain delimita com chaves ({}). Em seguida, o senhor cria um ChatPromptTemplate a partir do objeto review_template_str usando o método de classe .from_template().
Com review_template instanciado, o senhor pode passar context e question no modelo de string com review_template.format(). Os resultados podem parecer que o senhor não fez nada além de interpolação de string padrão do Pythonmas os modelos de prompt têm muitos recursos úteis que permitem a integração com modelos de bate-papo.
Observe como sua chamada anterior para review_template.format() gerou uma string com Humanos no início. Isso se deve ao fato de que o ChatPromptTemplate.from_template() assume que o modelo de cadeia de caracteres é uma mensagem humana por padrão. Para alterar isso, o senhor pode criar modelos de prompt mais detalhados para cada mensagem de chat que deseja que o modelo processe:
Nesse bloco, o senhor importa modelos de prompt separados para HumanMessage e SystemMessage. Em seguida, o senhor define uma string, review_system_template_str, que serve como modelo para um SystemMessage. Observe como o senhor declara apenas um context em review_system_template_str.
A partir disso, o senhor cria review_system_prompt que é um modelo de prompt específico para SystemMessage. Em seguida, o senhor cria um review_human_prompt para o HumanMessage. Observe como o template é apenas uma string com o parâmetro question variável.
Em seguida, o senhor adiciona review_system_prompt e review_human_prompt para uma lista chamada messages e crie review_prompt_templateque é o objeto final que engloba os modelos de prompt para o SystemMessage e para o HumanMessage. Chamada review_prompt_template.format_messages(context=context, question=question) gera uma lista com um SystemMessage e HumanMessageque podem ser passados para um modelo de bate-papo.
Para ver como combinar modelos de chat e modelos de prompt, o senhor criará uma cadeia com a LangChain Expression Language (LCEL). Isso ajuda o senhor a desbloquear a funcionalidade principal da LangChain de criar interfaces modulares personalizadas sobre modelos de chat.
Cadeias e linguagem de expressão LangChain (LCEL)
A cola que conecta modelos de bate-papo, prompts e outros objetos na LangChain é a cadeia. Uma cadeia nada mais é do que uma sequência de chamadas entre objetos no LangChain. A maneira recomendada de criar cadeias é usar a função Linguagem de Expressão LangChain (LCEL).
Para ver como isso funciona, dê uma olhada em como o senhor criaria uma cadeia com um modelo de chat e um modelo de prompt:
As linhas 1 a 42 são o que o senhor já fez. Ou seja, o senhor define review_prompt_template que é um modelo de prompt para responder a perguntas sobre avaliações de pacientes, e o senhor instancia um gpt-3.5-turbo-0125 chat model. Na linha 44, o senhor define review_chain com o | que é usado para encadear o review_prompt_template e chat_model juntos.
Isso cria um objeto, review_chain, que pode passar perguntas através do review_prompt_template e chat_model em uma única chamada de função. Em essência, isso abstrai todos os detalhes internos do review_chainpermitindo que o senhor interaja com a cadeia como se fosse um modelo de bate-papo.
Depois de salvar o modelo chatbot.pyatualizado, inicie uma nova sessão REPL na pasta do seu projeto básico. Veja como o senhor pode usar o review_chain:
Neste bloco, o senhor importa review_chain e define context e question como antes. Em seguida, o senhor passa um dicionário com as chaves context e question em review_chan.invoke(). Isso passa context e question por meio do modelo de prompt e do modelo de bate-papo para gerar uma resposta.
Observação: Ao chamar cadeias, o senhor pode usar todos os mesmos métodos que um modelo de bate-papo suporta.
Em geral, o LCEL permite que o senhor crie cadeias de comprimento arbitrário com o símbolo de pipe (|). Por exemplo, se o senhor quisesse formatar a resposta do modelo, poderia adicionar um analisador de saída para a cadeia:
Aqui, o senhor adiciona um StrOutputParser() à instância do review_chaino que tornará a resposta do modelo mais legível. Inicie uma nova sessão REPL e experimente:
Esse bloco é o mesmo de antes, só que agora o senhor pode ver que review_chain retorna uma string bem formatada em vez de um AIMessage.
O poder das cadeias está na criatividade e na flexibilidade que elas proporcionam ao senhor. O senhor pode encadear pipelines complexos para criar o seu chatbot e acabar com um objeto que executa o pipeline em uma única chamada de método. A seguir, o senhor colocará outro objeto em camadas no review_chain para recuperar documentos de um banco de dados vetorial.
Objetos de recuperação
O objetivo do review_chain é responder a perguntas sobre as experiências dos pacientes no hospital a partir de suas avaliações. Até agora, o senhor passou manualmente as avaliações como contexto para a pergunta. Embora isso possa funcionar para um pequeno número de avaliações, não é muito bom. Além disso, mesmo que o senhor consiga encaixar todas as avaliações na janela de contexto do modelo, não há garantia de que ele usará as avaliações corretas ao responder a uma pergunta.
Para superar isso, o senhor precisa de um retriever. O processo de recuperar documentos relevantes e passá-los a um modelo de linguagem para responder a perguntas é conhecido como geração aumentada por recuperação (RAG).
Para este exemplo, o senhor armazenará todas as avaliações em um arquivo banco de dados vetorial chamada ChromaDB. Se o senhor não estiver familiarizado com essa ferramenta de banco de dados e seus tópicos, consulte Embeddings e bancos de dados vetoriais com o ChromaDB antes de continuar.
O senhor pode instalar o ChromaDB com o seguinte comando:
Com isso instalado, o senhor pode usar o código a seguir para criar um banco de dados vetorial do ChromaDB com avaliações de pacientes:
Nas linhas 2 a 4, o senhor importa as dependências necessárias para criar o banco de dados vetorial. Em seguida, o senhor define REVIEWS_CSV_PATH e REVIEWS_CHROMA_PATHque são os caminhos onde os dados brutos das revisões são armazenados e onde o banco de dados vetorial armazenará os dados, respectivamente.
Mais adiante, o senhor terá uma visão geral dos dados do sistema hospitalar, mas por enquanto só precisa saber que reviews.csv armazena avaliações de pacientes. O senhor review na coluna reviews.csv é uma cadeia de caracteres com a avaliação do paciente.
Nas linhas 11 e 12, o senhor carrega as avaliações usando a função LangChain’s CSVLoader. Nas linhas 14 a 16, o senhor cria uma instância do ChromaDB a partir do reviews usando o modelo padrão de incorporação da OpenAI e armazena as incorporações de revisão em REVIEWS_CHROMA_PATH.
Nota: Na prática, se estiver incorporando um documento grande, o senhor deve usar um divisor de texto. Os divisores de texto dividem o documento em pedaços menores antes de executá-los por meio de um modelo de incorporação. Isso é importante porque os modelos de incorporação têm uma janela de contexto de tamanho fixo e, à medida que o tamanho do texto aumenta, a capacidade de uma incorporação de representar o texto com precisão diminui.
Para este exemplo, o senhor pode incorporar cada revisão individualmente porque elas são relativamente pequenas.
Em seguida, abra um terminal e execute o seguinte comando no diretório do projeto:
Isso deve levar apenas um minuto ou mais para ser executado e, depois disso, o senhor pode começar a realizar a pesquisa semântica nos embeddings de revisão:
O usuário importa as dependências necessárias para chamar o ChromaDB e especifica o caminho para os dados armazenados do ChromaDB em REVIEWS_CHROMA_PATH. Em seguida, o senhor carrega as variáveis de ambiente usando dotenv.load_dotenv() e criar um novo Chroma apontando para o seu banco de dados vetorial. Observe como o senhor precisa especificar novamente uma função de incorporação ao se conectar ao banco de dados vetorial. Certifique-se de que essa é a mesma função de incorporação que o senhor usou para criar os embeddings.
Em seguida, o senhor define uma pergunta e chama .similarity_search() no reviews_vector_db, passando em question e k=3. Isso cria um embedding para a pergunta e pesquisa no banco de dados vetorial os três embeddings de revisão mais semelhantes ao embedding da pergunta. Nesse caso, o senhor vê três avaliações em que os pacientes reclamaram da comunicação, que é exatamente o que o senhor pediu!
A última coisa a fazer é adicionar seu retriever de avaliações ao review_chain para que as avaliações relevantes sejam passadas para o prompt como contexto. Veja como o senhor faz isso:
Como antes, o senhor importa as dependências do ChromaDB, especifica o caminho para os dados do ChromaDB e instancia um novo Chroma novo objeto. Em seguida, o senhor cria o reviews_retriever chamando o .as_retriever() em reviews_vector_db para criar um objeto retriever que o senhor adicionará ao review_chain. Como o senhor especificou k=10o recuperador buscará as dez avaliações mais semelhantes à pergunta do usuário.
Em seguida, o senhor adiciona um dicionário com context e question chaves para a frente do review_chain. Em vez de passar o context manualmente, review_chain transmitirá sua pergunta ao retriever para obter as avaliações relevantes. Atribuição question a um RunnablePassthrough garante que a pergunta seja passada sem alterações para a próxima etapa da cadeia.
Agora o senhor tem uma cadeia totalmente funcional que pode responder a perguntas sobre as experiências dos pacientes a partir de suas avaliações. Inicie uma nova sessão REPL e experimente:
Como pode ver, o senhor só chama review_chain.invoke(question) para obter respostas aumentadas por recuperação sobre as experiências dos pacientes a partir de suas avaliações. O senhor aprimorará essa cadeia mais tarde, armazenando embeddings de avaliações, juntamente com outros metadados, no Neo4j.
Agora que o senhor entende os modelos de chat, prompts, cadeias e recuperação, está pronto para mergulhar no último conceito da LangChain: os agentes.
Agentes
Até agora, o senhor criou uma cadeia para responder a perguntas usando avaliações de pacientes. E se o senhor quiser que o seu chatbot também responda a perguntas sobre outros dados do hospital, como o tempo de espera do hospital? O ideal é que o seu chatbot possa alternar perfeitamente entre responder a perguntas sobre avaliações de pacientes e tempo de espera, dependendo da consulta do usuário. Para conseguir isso, o senhor precisará dos seguintes componentes:
- A cadeia de revisão de pacientes que o senhor já criou
- Uma função que pode consultar os tempos de espera em um hospital
- Uma maneira de um LLM saber quando deve responder a perguntas sobre experiências de pacientes ou consultar os tempos de espera
Para realizar o terceiro recurso, o senhor precisa de um agente.
Um agente é um modelo de linguagem que decide sobre uma sequência de ações a serem executadas. Ao contrário das cadeias, em que a sequência de ações é codificada, os agentes usam um modelo de linguagem para determinar quais ações devem ser executadas e em que ordem.
Antes de criar o agente, crie a seguinte função para gerar tempos de espera falsos para um hospital:
Em get_current_wait_time(), o senhor passa o nome de um hospital, verifica se é válido e gera um número aleatório para simular o tempo de espera. Na realidade, isso seria algum tipo de consulta ao banco de dados ou chamada de API, mas servirá para o mesmo propósito nesta demonstração.
Agora o senhor pode criar um agente que decide entre get_current_wait_time() e review_chain.invoke() dependendo da pergunta:
Nesse bloco, o senhor importa algumas dependências adicionais necessárias para criar o agente. Em seguida, o senhor define uma lista de Tool objetos. A Tool é uma interface que um agente usa para interagir com uma função. Por exemplo, a primeira ferramenta é denominada Reviews e chama o review_chain.invoke() se a pergunta atender aos critérios de description.
Observe como a description dá instruções ao agente sobre quando ele deve chamar a ferramenta. É aqui que as boas habilidades de engenharia de prompt são fundamentais para garantir que o LLM chame a ferramenta correta com as entradas corretas.
A segunda Tool em tools tem o nome de Waitse chama get_current_wait_time(). Novamente, o agente precisa saber quando usar o Waits e quais entradas passar para ela, dependendo do description.
Em seguida, o senhor inicializa um ChatOpenAI usando gpt-3.5-turbo-1106 como seu modelo de linguagem. Em seguida, o senhor cria um agente de funções OpenAI com create_openai_functions_agent(). Isso cria um agente projetado para passar entradas para funções. Ele faz isso retornando objetos JSON válidos que armazenam entradas de funções e seus valores correspondentes.
Para criar o tempo de execução do agente, o usuário passa o agente e as ferramentas para AgentExecutor. Configurações return_intermediate_steps e verbose para True permitirá que o senhor veja o processo de pensamento do agente e as ferramentas que ele utiliza.
Inicie uma nova sessão REPL para dar uma olhada em seu novo agente:
Primeiro, o senhor importa o agente e, em seguida, chama hospital_agent_executor.invoke() com uma pergunta sobre um tempo de espera. Conforme indicado no resultado, o agente sabe que o senhor está perguntando sobre um tempo de espera e passa C como entrada para o Waits ferramenta. A Waits chama a ferramenta get_current_wait_time(hospital="C") e retorna o tempo de espera correspondente para o agente. Em seguida, o agente usa esse tempo de espera para gerar sua saída final.
Um processo semelhante acontece quando o senhor pergunta ao agente sobre as avaliações da experiência do paciente, só que dessa vez o agente sabe que deve chamar o Reviews com o O que os pacientes disseram sobre seu conforto no
hospital? como entrada. O Reviews executa review_chain.invoke() usando sua pergunta completa como entrada, e o agente usa a resposta para gerar sua saída.
Esse é um recurso profundo. Os agentes dão aos modelos de linguagem a capacidade de executar praticamente qualquer tarefa para a qual o senhor possa escrever código. Imagine todos os incríveis e potencialmente perigosos chatbots que o senhor poderia criar com agentes.
Agora o senhor tem todos os pré-requisitos de conhecimento sobre LangChain necessários para criar um chatbot personalizado. A seguir, o senhor colocará seu chapéu de engenheiro de IA e aprenderá sobre os requisitos de negócios e os dados necessários para criar o chatbot do seu sistema hospitalar.
Todo o código que o senhor escreveu até agora foi criado para ensinar-lhe os fundamentos do LangChain e não será incluído no seu chatbot final. Sinta-se à vontade para começar com um diretório vazio na Etapa 2, onde o senhor começará a criar o seu chatbot.
Etapa 2: Entenda os requisitos de negócios e os dados
Antes de começar a trabalhar em qualquer projeto de IA, o senhor precisa entender o problema que deseja resolver e fazer um plano de como irá resolvê-lo. Isso envolve a definição clara do problema, a coleta de requisitos, a compreensão dos dados e da tecnologia disponíveis e o estabelecimento de expectativas claras com as partes interessadas. Para este projeto, o senhor começará definindo o problema e reunindo requisitos de negócios para o seu chatbot.
Entenda o problema e os requisitos
Imagine que o senhor é um engenheiro de IA que trabalha para um grande sistema hospitalar nos EUA. Suas partes interessadas gostariam de ter mais visibilidade dos dados em constante mudança que coletam. Eles querem respostas para perguntas ad-hoc sobre pacientes, visitas, médicos, hospitais e pagadores de seguros sem precisar entender uma linguagem de consulta como SQL, solicitar um relatório a um analista ou esperar que alguém crie um painel de controle.
Para conseguir isso, as partes interessadas querem uma ferramenta de chatbot interna, semelhante ao ChatGPT, que possa responder a perguntas sobre os dados da empresa. Após uma reunião para reunir os requisitos, o senhor recebe uma lista dos tipos de perguntas que o chatbot deve responder:
- Qual é o tempo de espera atual no hospital XYZ?
- Qual hospital tem atualmente o menor tempo de espera?
- Em quais hospitais os pacientes estão reclamando de problemas de faturamento e seguro?
- Algum paciente reclamou da falta de limpeza do hospital?
- O que os pacientes disseram sobre como os médicos e enfermeiros se comunicam com eles?
- O que os pacientes estão dizendo sobre a equipe de enfermagem do hospital XYZ?
- Qual foi o valor total do faturamento cobrado da Cigna pagadores em 2023?
- Quantos pacientes o Dr. John Doe tratou?
- Quantas consultas estão abertas e qual é a duração média delas em dias?
- Qual médico tem a menor duração média de visitas em dias?
- Quanto foi cobrado pela estadia do paciente 789?
- Qual hospital trabalhou com o maior número de pacientes da Cigna em 2023?
- Qual é o valor médio de faturamento para visitas de emergência por hospital?
- Em qual estado houve o maior aumento percentual de visitas ao Medicaid de 2022 a 2023?
O senhor pode responder a perguntas como Qual foi o valor total de faturamento cobrado dos pagadores da Cigna em 2023? com estatísticas agregadas usando uma linguagem de consulta como SQL. O mais importante é que essas perguntas têm uma única resposta objetiva. O senhor poderia executar consultas predefinidas para respondê-las, mas sempre que uma parte interessada tiver uma pergunta nova ou ligeiramente matizada, será necessário escrever uma nova consulta. Para evitar isso, o seu chatbot deve gerar consultas precisas de forma dinâmica.
Perguntas como Algum paciente reclamou da falta de limpeza do hospital? ou O que os pacientes disseram sobre como os médicos e enfermeiros se comunicam com eles? são mais subjetivas e podem ter muitas respostas aceitáveis. Seu chatbot precisará ler documentos, como avaliações de pacientes, para responder a esses tipos de perguntas.
Em última análise, as partes interessadas querem uma única interface de bate-papo que possa responder perfeitamente a perguntas subjetivas e objetivas. Isso significa que, ao receber uma pergunta, o seu chatbot precisa saber que tipo de pergunta está sendo feita e de qual fonte de dados deve ser extraída.
Por exemplo, se for perguntado Quanto foi cobrado pela estadia do paciente 789?, seu chatbot deve saber que precisa consultar um banco de dados para encontrar a resposta. Se for perguntado O que os pacientes disseram sobre como os médicos e enfermeiros se comunicam com eles?Se o seu chatbot não estiver funcionando, ele deve saber que precisa ler e resumir as avaliações dos pacientes.
A seguir, o senhor explorará os dados que o sistema do seu hospital registra, o que é, sem dúvida, o pré-requisito mais importante para a criação do seu chatbot.
Explore os dados disponíveis
Antes de criar o seu chatbot, o senhor precisa ter uma compreensão completa dos dados que ele usará para responder às consultas dos usuários. Isso o ajudará a determinar o que é viável e como deseja estruturar os dados para que o chatbot possa acessá-los facilmente. Todos os dados que o senhor usará neste artigo foram gerados sinteticamente, e grande parte deles foi derivada de um popular conjunto de dados de assistência médica no Kaggle.
Na prática, os conjuntos de dados a seguir provavelmente seriam armazenados como tabelas em um banco de dados SQL, mas o senhor trabalhará com arquivos CSV para manter o foco na criação do chatbot. Esta seção fornecerá uma descrição detalhada de cada arquivo CSV.
O senhor precisará colocar todos os arquivos CSV que fazem parte deste projeto no seu data/ antes de continuar com o tutorial. Certifique-se de que os baixou dos materiais e os colocou em sua pasta data/ :
hospitais.csv
O hospitals.csv registra informações sobre cada hospital que sua empresa administra. Há 30 hospitais e três campos neste arquivo:
hospital_id: Um número inteiro que identifica exclusivamente um hospital.hospital_name: O nome do hospital.hospital_state: O estado em que o hospital está localizado.
Se o senhor estiver familiarizado com os bancos de dados SQL tradicionais e com o esquema estrelao senhor pode pensar em hospitals.csv como um tabela de dimensões. As tabelas de dimensão são relativamente curtas e contêm informações descritivas ou atributos que fornecem contexto para os dados na tabelas de fatos. As tabelas de fatos registram eventos sobre as entidades armazenadas nas tabelas de dimensões e tendem a ser tabelas mais longas.
Nesse caso, hospitals.csv registra informações específicas de hospitais, mas o senhor pode uni-las a tabelas de fatos para responder a perguntas sobre quais pacientes, médicos e pagadores estão relacionados ao hospital. Isso ficará mais claro quando o senhor explorar visits.csv.
Se estiver curioso, o senhor pode inspecionar as primeiras linhas do hospitals.csv usando uma biblioteca de dataframe como a Polares. Certifique-se de que o Polars seja instalado no seu ambiente virtuale execute o seguinte código:
Nesse bloco de código, o senhor importa o Polars, define o caminho para o hospitals.csv, lê os dados em um Polars DataFrame, exibe a forma dos dados e exibe as primeiras 5 linhas. Isso mostra ao senhor, por exemplo, que Walton, LLC O hospital tem um ID de 2 e está localizado no estado da Flórida, FL.
médicos.csv
O physicians.csv contém dados sobre os médicos que trabalham para seu sistema hospitalar. Esse conjunto de dados tem os seguintes campos:
physician_id: Um número inteiro que identifica exclusivamente cada médico.physician_name: O nome do médico.physician_dob: A data de nascimento do médico.physician_grad_year: O ano em que o médico se formou na faculdade de medicina.medical_school: Onde o médico cursou a faculdade de medicina.salary: O salário do médico.
Esses dados podem ser considerados novamente como uma tabela de dimensão, e o senhor pode inspecionar as primeiras linhas usando Polars:
Como o senhor pode ver no bloco de código, há 500 médicos em physicians.csv. As primeiras linhas de physicians.csv dão ao senhor uma ideia de como são os dados. Por exemplo, Heather Smith tem um ID de médico 3, nasceu em 15 de junho de 1965, formou-se em medicina em 15 de junho de 1995, frequentou a NYU Grossman Medical School e seu salário é de aproximadamente US$ 295.239.
payers.csv
O próximo arquivo, payers.csvregistra informações sobre as companhias de seguro que seus hospitais cobram pelas visitas dos pacientes. Semelhante ao hospitals.csv, é um arquivo pequeno com alguns campos:
payer_id: Um número inteiro que identifica exclusivamente cada pagador.payer_name: O nome da empresa do pagador.
Os únicos cinco pagadores nos dados são Medicaid, UnitedHealthcare, Aetna, Cignae Cruz Azul. Suas partes interessadas estão muito interessadas na atividade dos pagadores, portanto payers.csv será útil quando estiver conectado a pacientes, hospitais e médicos.
reviews.csv
O reviews.csv contém comentários de pacientes sobre sua experiência no hospital. Ele tem os seguintes campos:
review_id: Um número inteiro que identifica exclusivamente uma revisão.visit_id: Um número inteiro que identifica a visita do paciente sobre a qual a avaliação foi feita.review: Essa é a avaliação de texto de forma livre deixada pelo paciente.physician_name: O nome do médico que tratou o paciente.hospital_name: O hospital onde o paciente ficou.patient_name: O nome do paciente.
Esse conjunto de dados é o primeiro que o senhor viu que contém o texto livre revisão e seu chatbot deve usá-lo para responder a perguntas sobre detalhes de avaliações e experiências de pacientes.
Veja o que o reviews.csv se parece:
Há 1005 avaliações nesse conjunto de dados, e o senhor pode ver como cada avaliação está relacionada a uma visita. Por exemplo, a avaliação com ID 9 corresponde à visita ID 8138, e as primeiras palavras são “The hospital’s commitment to pat…”. O senhor deve estar se perguntando como pode conectar uma avaliação a um paciente ou, de forma mais geral, como pode conectar todos os conjuntos de dados descritos até agora entre si. É aqui que o senhor visits.csv entra em cena.
visits.csv
O último arquivo, visits.csv, registra detalhes sobre cada visita hospitalar que sua empresa atendeu. Continuando com a analogia do esquema em estrela, o senhor pode pensar em visits.csv como um tabela de fatos que conecta hospitais, médicos, pacientes e pagadores. Aqui estão os campos:
visit_id: O identificador exclusivo de uma visita ao hospital.patient_id: O ID do paciente associado à visita.date_of_admission: A data em que o paciente foi admitido no hospital.room_number: O número do quarto do paciente.admission_type: Uma das opções “Elective” (eletiva), “Emergency” (emergência) ou “Urgent” (urgente).chief_complaint: Uma cadeia de caracteres que descreve o principal motivo pelo qual o paciente está no hospital.primary_diagnosis: Uma cadeia de caracteres que descreve o diagnóstico primário feito pelo médico.treatment_description: Um resumo em texto do tratamento dado pelo médico.test_results: Uma das opções “Inconclusive” (Inconclusivo), “Normal” (Normal) ou “Abnormal” (Anormal).discharge_date: A data em que o paciente recebeu alta do hospitalphysician_id: O ID do médico que tratou o paciente.hospital_id: A ID do hospital em que o paciente ficou.payer_id: A ID do pagador do seguro usado pelo paciente.billing_amount: O valor cobrado do pagador pela visita.visit_status: Uma das opções “OPEN” ou “DISCHARGED”.
Esse conjunto de dados fornece tudo o que o senhor precisa para responder a perguntas sobre o relacionamento entre cada entidade hospitalar. Por exemplo, se o senhor souber o ID de um médico, poderá usar visits.csv para descobrir a quais pacientes, pagadores e hospitais o médico está associado. Dê uma olhada no que o visits.csv aparece no Polars:
O senhor pode ver que há 9998 visitas registradas junto com os 15 campos descritos acima. Observe que chief_complaint, treatment_description, e primary_diagnosis podem estar faltando em uma visita. O senhor terá de ter isso em mente, pois as partes interessadas podem não estar cientes de que muitas visitas estão sem dados críticos – isso pode ser um insight valioso por si só! Por fim, observe que, quando uma visita ainda está aberta, o discharged_date estará faltando.
Agora, o senhor tem uma compreensão dos dados que usará para criar o chatbot que as partes interessadas desejam. Para recapitular, os arquivos são divididos para simular a aparência de um banco de dados SQL tradicional. Todos os hospitais, pacientes, médicos, revisões e pagadores estão conectados por meio de visits.csv.
Tempos de espera
O senhor deve ter notado que não há dados para responder a perguntas como Qual é o tempo de espera atual no hospital XYZ? ou
Qual hospital tem atualmente o menor tempo de espera?. Infelizmente, o sistema do hospital não registra o histórico de tempos de espera. Seu chatbot terá de chamar uma API para obter informações sobre o tempo de espera atual. O senhor verá como isso funciona mais tarde.
Com uma compreensão dos requisitos comerciais, dos dados disponíveis e das funcionalidades do LangChain, o senhor pode criar um projeto para o seu chatbot.
Projetar o chatbot
Agora que o senhor conhece os requisitos comerciais, os dados e os pré-requisitos do LangChain, está pronto para projetar o seu chatbot. Um bom projeto dá ao senhor e a outras pessoas uma compreensão conceitual dos componentes necessários para criar o seu chatbot. Seu projeto deve ilustrar claramente como os dados fluem pelo seu chatbot e deve servir como uma referência útil durante o desenvolvimento.
Seu chatbot usará várias ferramentas para responder a diversas perguntas sobre o sistema do seu hospital. Aqui está um fluxograma que ilustra como o senhor fará isso:
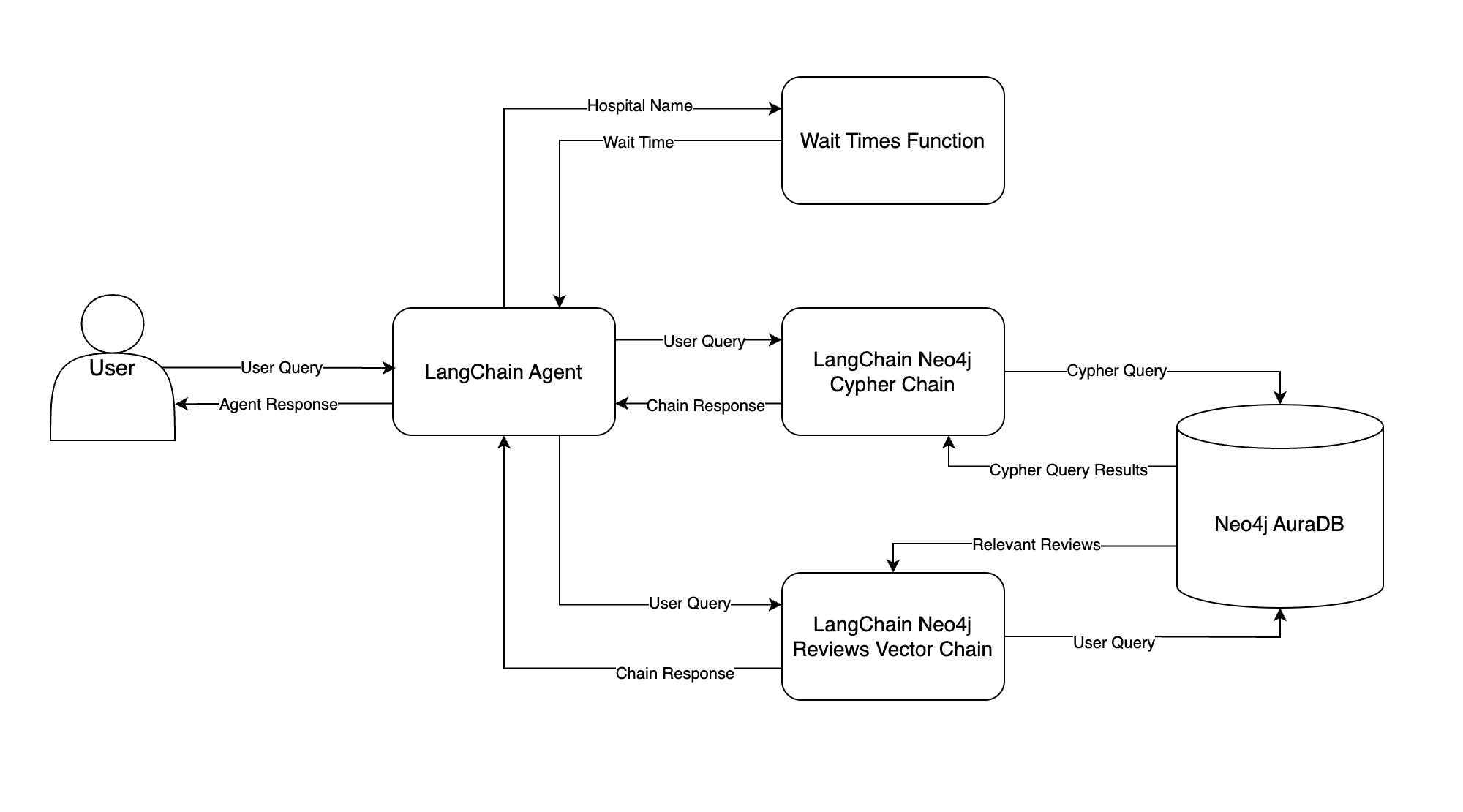
Esse fluxograma ilustra como os dados passam pelo seu chatbot, começando pela consulta de entrada do usuário até a resposta final. Aqui está um resumo de cada componente:
- Agente LangChain: O agente LangChain é o cérebro do seu chatbot. Com base em uma consulta do usuário, o agente decide qual ferramenta chamar e o que fornecer à ferramenta como entrada. Em seguida, o agente observa o resultado da ferramenta e decide o que retornar ao usuário – essa é a resposta do agente.
- Neo4j AuraDB: O senhor armazenará os dados estruturados do sistema hospitalar e as avaliações dos pacientes em um banco de dados gráfico Neo4j AuraDB. O senhor aprenderá tudo sobre isso na próxima seção.
- Cadeia LangChain Neo4j Cypher: Essa cadeia tenta converter a consulta do usuário em Cypher, a linguagem de consulta do Neo4j, e executar a consulta Cypher no Neo4j. Em seguida, a cadeia responde à consulta do usuário usando os resultados da consulta Cypher. A resposta da cadeia é devolvida ao agente LangChain e enviada ao usuário.
- LangChain Neo4j Reviews Vector Chain: Isso é muito semelhante à cadeia que o senhor criou no Etapa 1só que agora os embeddings das avaliações dos pacientes são armazenados no Neo4j. A cadeia procura por avaliações relevantes com base naquelas semanticamente semelhantes à consulta do usuário, e as avaliações são usadas para responder à consulta do usuário.
- Função de tempos de espera: Semelhante à lógica do Etapa 1, o agente LangChain tenta extrair um nome de hospital da consulta do usuário. O nome do hospital é passado como entrada para uma função Python que obtém os tempos de espera, e o tempo de espera é retornado ao agente.
Para dar um exemplo, suponha que um usuário pergunte Quantas visitas de emergência foram feitas em 2023? O agente da LangChain receberá essa pergunta e decidirá para qual ferramenta, se houver, passará a pergunta. Nesse caso, o agente deve passar a pergunta para a ferramenta Cadeia LangChain Neo4j Cypher. A cadeia tentará converter a pergunta em uma consulta Cypher, executará a consulta Cypher no Neo4j e usará os resultados da consulta para responder à pergunta.
Depois que a cadeia LangChain Neo4j Cypher responder à pergunta, ela retornará a resposta ao agente, e o agente transmitirá a resposta ao usuário.
Com esse design em mente, o senhor pode começar a criar seu chatbot. Sua primeira tarefa é configurar uma instância do Neo4j AuraDB para o acesso do chatbot.
Etapa 3: Configurar um banco de dados gráfico do Neo4j
Como o senhor viu em passo 2Se o senhor não tem acesso aos dados do seu sistema hospitalar, eles estão atualmente armazenados em arquivos CSV. Antes de criar o seu chatbot, o senhor precisa armazenar esses dados em um banco de dados que o chatbot possa consultar. O senhor usará Neo4j AuraDB para isso.
Antes de aprender a configurar uma instância do Neo4j AuraDB, o senhor terá uma visão geral dos bancos de dados de grafos e verá por que usar um banco de dados de grafos pode ser uma opção melhor do que um banco de dados relacional para este projeto.
Uma breve visão geral dos bancos de dados de grafos
Os bancos de dados de gráficos, como o Neo4j, são bancos de dados projetados para representar e processar dados armazenados como um gráfico. Os dados de gráficos consistem em nós, bordas ou relacionamentose propriedades. Os nós representam entidades, os relacionamentos conectam entidades e as propriedades fornecem metadados adicionais sobre nós e relacionamentos.
Por exemplo, veja como o senhor pode representar os nós e os relacionamentos do sistema hospitalar em um gráfico:
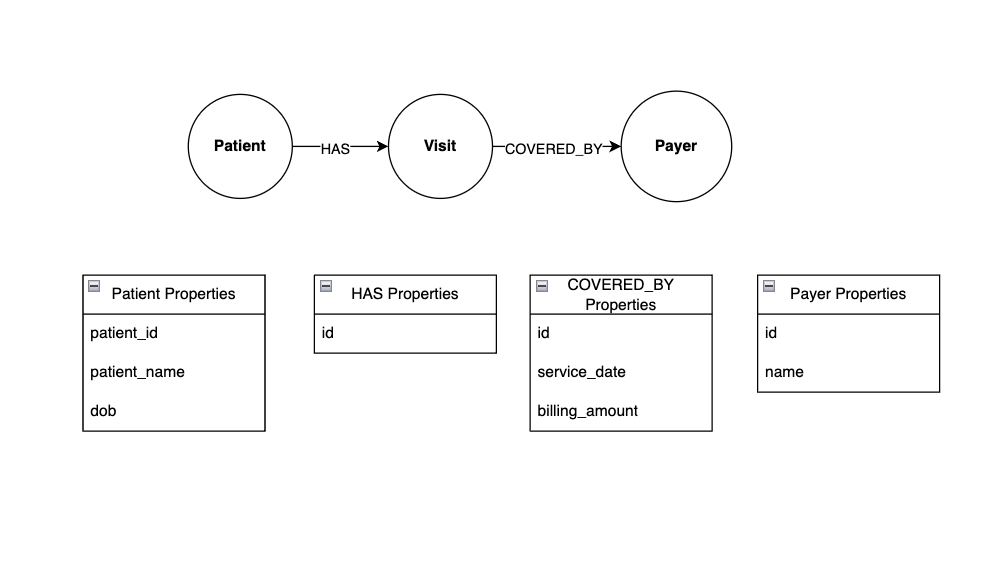
Esse gráfico tem três nós – Paciente, Visitee Pagador. Paciente e Visite estão conectados pelo HAS indicando que um paciente de hospital tem uma visita. Da mesma forma, Visita e Pagador são conectados pelo COVERED_BY indicando que um pagador de seguro cobre uma visita ao hospital.
Observe como os relacionamentos são representados por uma seta que indica sua direção. Por exemplo, a direção da seta HAS diz ao senhor que um paciente pode ter uma visita, mas uma visita não pode ter um paciente.
Tanto os nós quanto os relacionamentos podem ter propriedades. Neste exemplo, Paciente têm propriedades de id, nome e data de nascimento, e os nós COVERED_BY tem propriedades de data de serviço e valor de faturamento. O armazenamento de dados em um gráfico como esse tem várias vantagens:
-
Simplicidade: A modelagem de relacionamentos do mundo real entre entidades é natural em bancos de dados de gráficos, reduzindo a necessidade de esquemas complexos que exigem várias operações de junção para responder a consultas.
-
Relacionamentos: Os bancos de dados gráficos são excelentes para lidar com relacionamentos complexos. A passagem pelas relações é eficiente, facilitando a consulta e a análise de dados conectados.
-
Flexibilidade: Os bancos de dados de grafos não têm esquema, o que permite uma fácil adaptação às estruturas de dados em constante mudança. Essa flexibilidade é benéfica para a evolução dos modelos de dados.
-
Desempenho: A recuperação de dados conectados é mais rápida em bancos de dados gráficos do que em bancos de dados relacionais, especialmente em cenários que envolvem consultas complexas com vários relacionamentos.
-
Correspondência de padrões: Os bancos de dados de grafos oferecem suporte a poderosas consultas de correspondência de padrões, facilitando a expressão e a localização de estruturas específicas nos dados.
Quando o senhor tem dados com muitos relacionamentos complexos, a simplicidade e a flexibilidade dos bancos de dados de gráficos facilitam o projeto e a consulta em comparação com os bancos de dados relacionais. Como o senhor verá mais adiante, a especificação de relacionamentos em consultas de bancos de dados de grafos é concisa e não envolve junções complicadas. Se o senhor estiver interessado, o Neo4j ilustra bem isso com um exemplo realista de banco de dados em seu documentação.
Devido a essa representação concisa dos dados, há menos espaço para erros quando um LLM gera consultas a bancos de dados de gráficos. Isso ocorre porque o senhor só precisa informar ao LLM os nós, os relacionamentos e as propriedades do seu banco de dados de gráficos. Em contraste com os bancos de dados relacionais, em que o LLM precisa navegar e reter o conhecimento dos esquemas de tabela e dos relacionamentos de chave estrangeira em todo o banco de dados, deixando mais espaço para erros na geração de SQL.
A seguir, o senhor começará a trabalhar com bancos de dados gráficos configurando um Neo4j AuraDB . Depois disso, o senhor moverá o sistema do hospital para a instância do Neo4j e aprenderá a consultá-lo.
Criar uma conta do Neo4j e uma instância do AuraDB
Para começar a usar o Neo4j, o senhor pode criar uma conta gratuita no Neo4j AuraDB conta. A página de destino deve ser semelhante a esta:
Clique no botão Iniciar gratuitamente e crie uma conta. Depois de fazer login, o usuário verá o console do Neo4j Aura:
Clique em Nova instância e crie uma instância livre. Deve aparecer um modal semelhante a este:
Depois que o senhor clicar em Faça o download e continue, sua instância deverá ser criada e um arquivo de texto contendo as credenciais do banco de dados Neo4j deverá ser baixado. Depois que a instância for criada, o senhor verá que seu status é Em execução. Ainda não deve haver nós ou relacionamentos:
Em seguida, abra o arquivo de texto que você baixou com suas credenciais do Neo4j e copie o NEO4J_URI, NEO4J_USERNAME, e NEO4J_PASSWORD em seu .env arquivo:
O senhor usará essas variáveis de ambiente para se conectar à instância do Neo4j em Python para que o chatbot possa executar consultas.
Observação: Por padrão, o senhor NEO4J_URI deve ser semelhante ao neo4j+s://
Agora o senhor tem tudo pronto para interagir com a instância do Neo4j. Em seguida, o senhor projetará o banco de dados gráfico do sistema hospitalar. Isso lhe dirá como as entidades do hospital estão relacionadas e informará os tipos de consultas que o senhor pode executar.
Projetar o banco de dados gráfico do sistema hospitalar
Agora que o senhor tem uma instância do Neo4j AuraDB em execução, precisa decidir quais nós, relacionamentos e propriedades deseja armazenar. Uma das formas mais populares de representar isso é por meio de um fluxograma. Com base no seu entendimento dos dados do sistema hospitalar, o senhor chegou ao seguinte design:
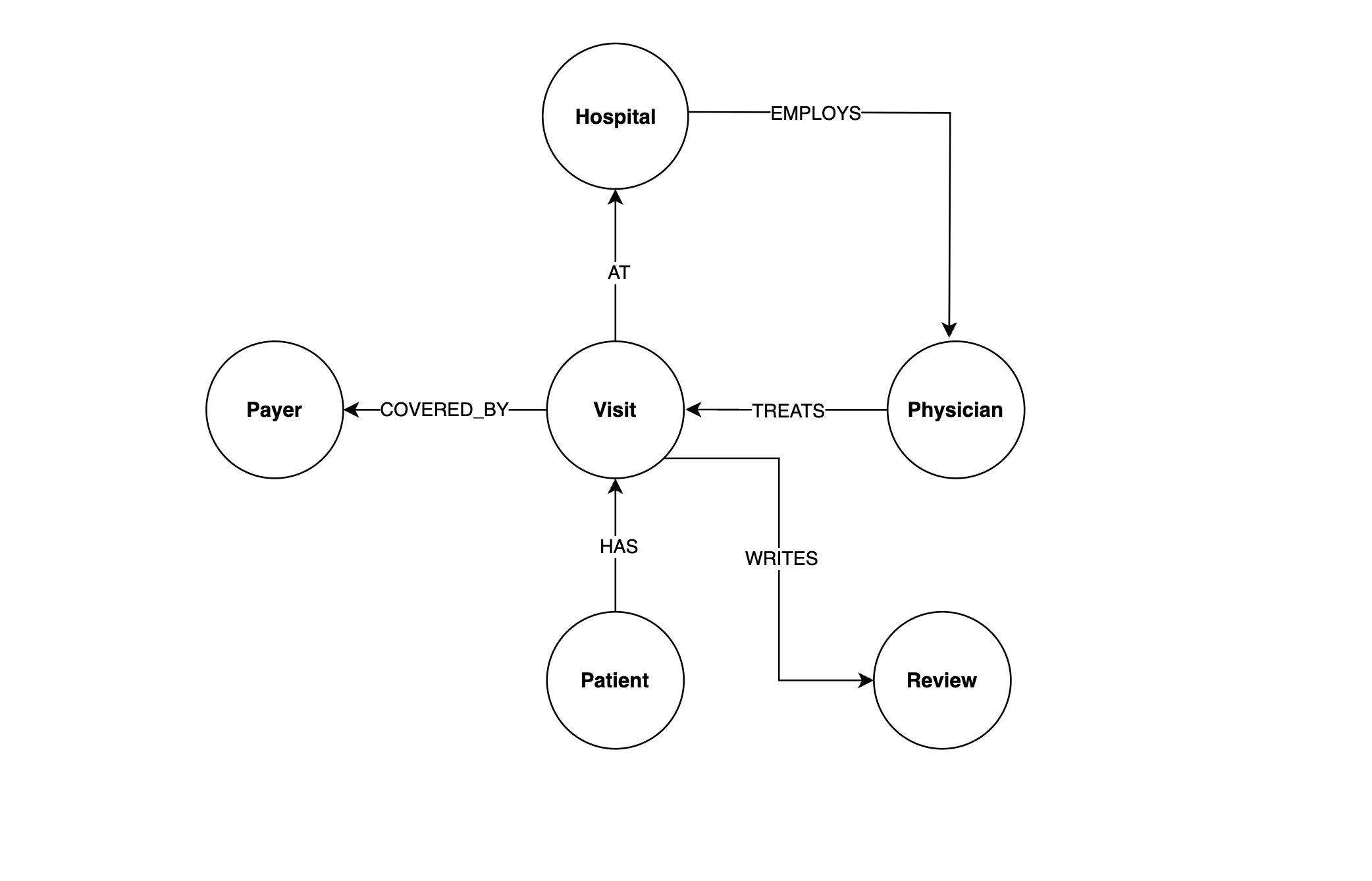
Esse diagrama mostra ao senhor todos os nós e relacionamentos nos dados do sistema hospitalar. Uma maneira útil de pensar sobre esse fluxograma é começar com o Paciente e seguir os relacionamentos. A Paciente tem a visita em a hospitale o hospital empregados a médico para tratar o visita que é coberto pelo um seguro pagador.
Aqui estão as propriedades armazenadas em cada nó:
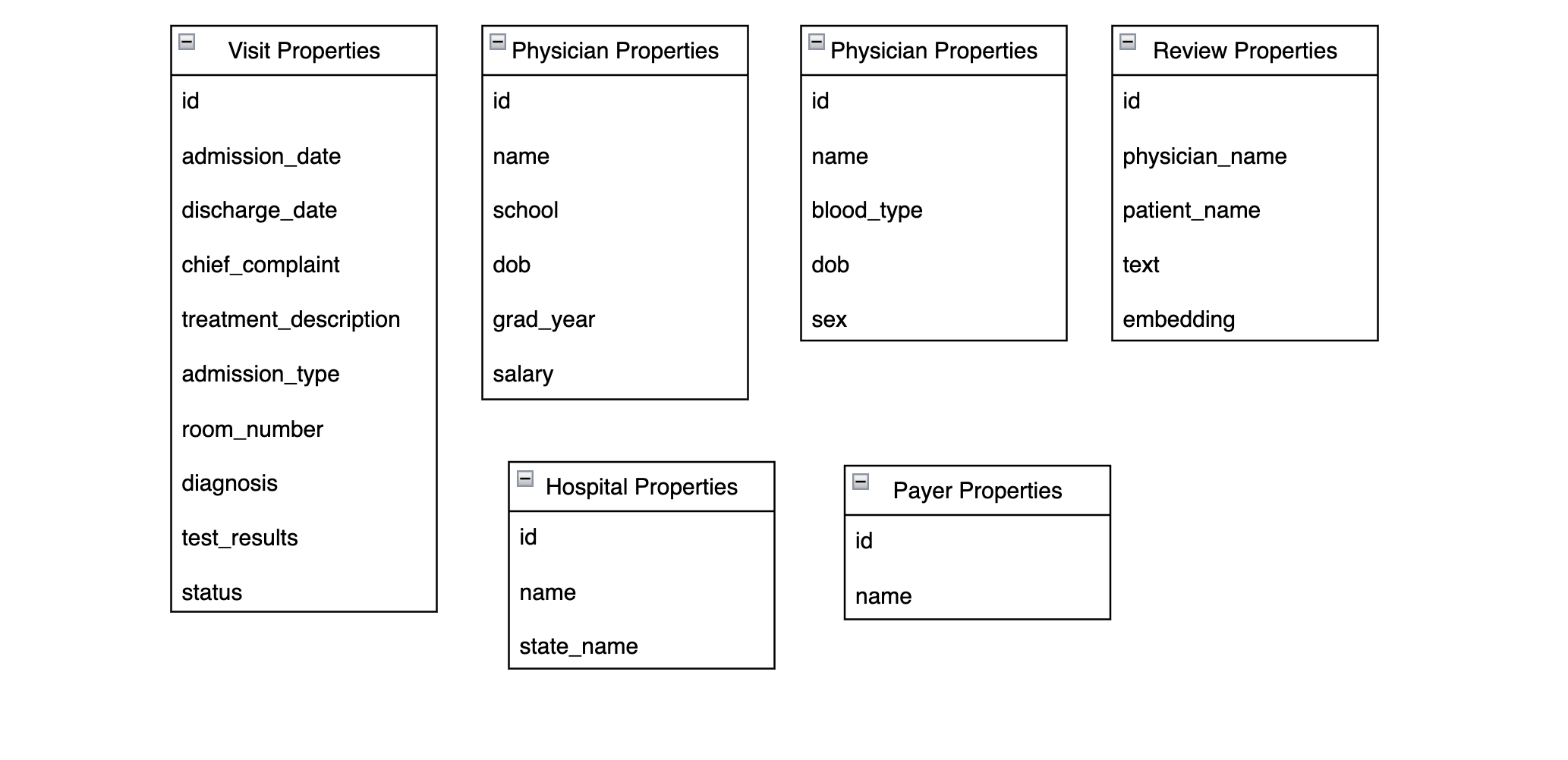
A maioria dessas propriedades vem diretamente dos campos que o senhor explorou em etapa 2. Uma diferença notável é que o Revisão Os nós têm um incorporação que é uma representação vetorial da propriedade nome_do_paciente, nome_do_médicoe texto propriedades. Isso permite que o senhor faça pesquisas de vetores em nós de revisão, como o senhor fez com o ChromaDB.
Aqui estão as propriedades de relacionamento:
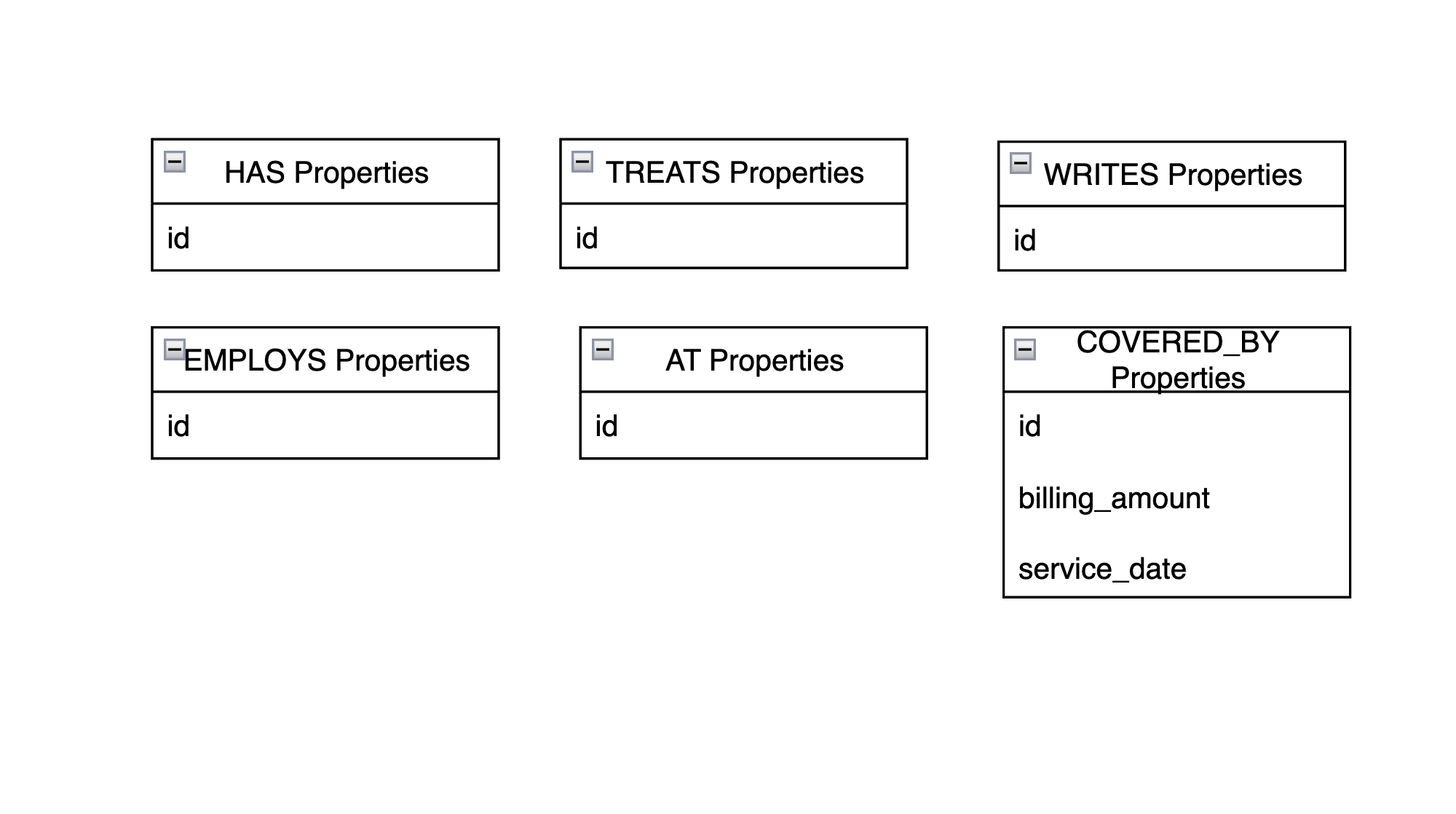
Como o senhor pode ver, COVERED_BY é o único relacionamento com mais de um id propriedade. O service_date é a data em que o paciente recebeu alta de uma consulta, e billing_amount é o valor cobrado do pagador pela visita.
Nota: Esses dados falsos do sistema hospitalar têm um número relativamente pequeno de nós e relacionamentos em relação ao que o senhor veria normalmente em um ambiente empresarial. No entanto, o senhor pode facilmente imaginar quantos nós e relacionamentos a mais poderia adicionar a um sistema hospitalar real. Por exemplo, enfermeiros, farmacêuticos, farmácias, medicamentos prescritos, cirurgias, parentes de pacientes e muitas outras entidades hospitalares poderiam ser representadas como nós.
O senhor também poderia redesenhar isso de modo que os diagnósticos e sintomas fossem representados como nós em vez de propriedades, ou poderia adicionar mais propriedades de relacionamento. Tudo isso poderia ser feito sem alterar o design que o senhor já tem. Essa é a beleza dos gráficos – o senhor simplesmente adiciona mais nós e relacionamentos à medida que os dados evoluem.
Agora que o senhor tem uma visão geral do projeto do sistema hospitalar que usará, é hora de transferir seus dados para o Neo4j!
Carregar dados para o Neo4j
Com uma instância do Neo4j em execução e um entendimento dos nós, propriedades e relacionamentos que deseja armazenar, o senhor pode mover os dados do sistema do hospital para o Neo4j. Para isso, o senhor criará uma pasta chamada hospital_neo4j_etl com alguns arquivos vazios. O senhor também deverá criar uma pasta docker-compose.yml no diretório raiz do seu projeto:
./
│
├── hospital_neo4j_etl/
│ │
│ ├── src/
│ │ ├── entrypoint.sh
│ │ └── hospital_bulk_csv_write.py
│ │
│ ├── Dockerfile
│ └── pyproject.toml
│
├── .env
└── docker-compose.yml
O senhor .env deve ter as seguintes variáveis de ambiente:
Observe que o senhor armazenou todos os arquivos CSV em um local público em GitHub. Como a instância do Neo4j AuraDB está sendo executada na nuvem, ela não pode acessar arquivos no computador local, e o senhor precisa usar HTTP ou fazer upload dos arquivos diretamente para a instância. Para este exemplo, o senhor pode usar o link acima ou carregar os dados em outro local.
Observação: Se o senhor estiver carregando dados proprietários para o Neo4j, certifique-se sempre de que eles estejam armazenados em um local seguro e transferidos adequadamente. Os dados usados para este projeto são todos sintéticos e não proprietários, portanto, não há problema em carregá-los por meio de uma conexão HTTP pública. No entanto, na prática, isso não seria uma boa ideia. O senhor pode ler mais sobre maneiras seguras de importar dados para o Neo4j em sua documentação.
Quando o senhor tiver seu .env preenchido, abra o arquivo pyproject.tomlque fornece a configuração, os metadados e as dependências definidas no arquivo TOML formato:
Este projeto é um projeto básico processo de extração, transformação e carregamento (ETL) que transfere os dados para o Neo4j, portanto, suas únicas dependências são neo4j e tentar novamente. O script principal do ETL é hospital_neo4j_etl/src/hospital_bulk_csv_write.py. É muito longo para incluir o script completo aqui, mas o senhor terá uma ideia das principais etapas hospital_neo4j_etl/src/hospital_bulk_csv_write.py são executadas. O senhor pode copiar o script completo dos materiais:
Primeiro, o senhor importa as dependências, carrega as variáveis de ambiente e configura o registro:
O senhor importa o GraphDatabase da classe neo4j para se conectar à sua instância em execução. Observe aqui que o senhor não está mais usando o Python-dotenv para carregar variáveis de ambiente. Em vez disso, o senhor passará as variáveis de ambiente para o contêiner do Docker que executa o script. Em seguida, o senhor definirá funções para mover os dados do hospital para o Neo4j de acordo com o seu projeto:
Primeiro, o senhor define uma função auxiliar, _set_uniqueness_constraints()que cria e executa consultas que exigem que cada nó tenha um ID exclusivo.
Em load_hospital_graph_from_csv()o senhor instancia um driver que se conecta à sua instância do Neo4j e define restrições de exclusividade para cada nó do sistema hospitalar.
Observe que o @retry decorador anexado a load_hospital_graph_from_csv(). Se o load_hospital_graph_from_csv() falhar por qualquer motivo, esse decorador o executará cem vezes com um atraso de dez segundos entre as tentativas. Isso é útil quando há problemas intermitentes de conexão com o Neo4j, que geralmente são resolvidos com a recriação da conexão. No entanto, não deixe de verificar os registros do script para ver se um erro ocorre mais do que algumas vezes.
Próximo, load_hospital_graph_from_csv() carrega dados para cada nó e relação:
Cada nó e relacionamento é carregado de seus respectivos arquivos csv e gravado no Neo4j de acordo com o projeto do banco de dados de gráficos. No final do script, o senhor chama load_hospital_graph_from_csv() no campo nome-idioma principale todos os dados devem ser preenchidos em sua instância do Neo4j.
Depois de escrever hospital_neo4j_etl/src/hospital_bulk_csv_write.py, o senhor pode definir um entrypoint.sh que será executado quando o contêiner do Docker for iniciado:
Esse arquivo de ponto de entrada não é tecnicamente necessário para este projeto, mas é uma boa prática ao criar contêineres, pois permite executar os comandos de shell necessários antes de executar o script principal.
O último arquivo a ser escrito para o ETL é o arquivo Docker. Ele tem a seguinte aparência:
Este Dockerfile diz ao seu contêiner para usar o python:3.11-slim distribuição, copie o conteúdo de hospital_neo4j_etl/src/ para o arquivo /app no diretório do contêiner, instale as dependências do pyproject.tomle execute entrypoint.sh.
Agora o senhor pode adicionar este projeto ao docker-compose.yml:
O ETL será executado como um serviço chamado hospital_neo4j_etle executará o Dockerfile em ./hospital_neo4j_etl usando variáveis de ambiente do .env. Como o senhor tem apenas um contêiner, ainda não precisa do docker-compose. No entanto, adicionará mais contêineres para orquestrar com seu ETL na próxima seção, portanto, é útil começar com o docker-compose.yml.
Para executar seu ETL, abra um terminal e execute:
Quando o ETL terminar de ser executado, retorne ao console do Aura:
Clique em Abrir e o senhor será solicitado a digitar sua senha do Neo4j. Depois de fazer login com êxito na instância, o senhor verá uma tela semelhante a esta:
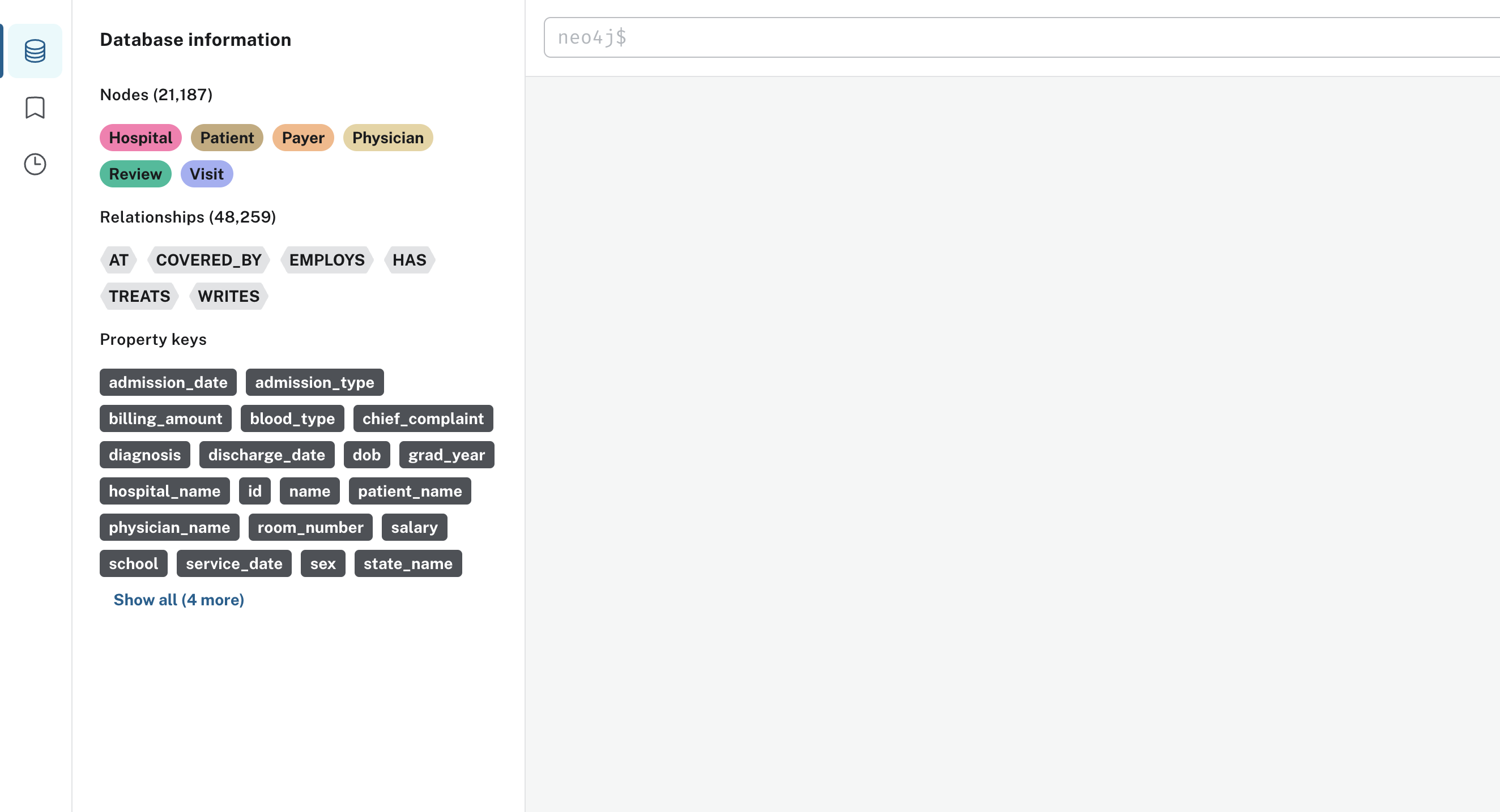
Como o senhor pode ver em Informações sobre o banco de dados, todos os nós, relacionamentos e propriedades foram carregados. Há 21.187 nós e 48.259 relacionamentos. O senhor está pronto para começar a escrever consultas!
Consultar o gráfico do sistema hospitalar
A última coisa que o senhor precisa fazer antes de criar seu chatbot é se familiarizar com o Cypher sintaxe. Cypher é a linguagem de consulta do Neo4j e é bastante intuitiva de aprender, especialmente se o senhor estiver familiarizado com SQL. Esta seção abordará os conceitos básicos, e isso é tudo de que o senhor precisa para criar o chatbot. O senhor pode conferir a documentação do Neo4j para obter uma visão geral mais abrangente do Cypher.
A palavra-chave mais comumente usada para ler dados em Cypher é MATCHe é usada para especificar padrões a serem procurados no gráfico. O padrão mais simples é aquele com um único nó. Por exemplo, se o senhor quisesse encontrar os cinco primeiros nós de pacientes gravados no gráfico, poderia executar a seguinte consulta Cypher:
Nessa consulta, o senhor está fazendo a correspondência com Patient nós. No Cypher, os nós são sempre indicados por parênteses. O p em (p:Patient) é um alias que o senhor pode referenciar posteriormente na consulta. RETURN p LIMIT 5; diz ao Neo4j para retornar apenas cinco nós de pacientes. O senhor pode executar essa consulta na interface do usuário do Neo4j e os resultados devem ter a seguinte aparência:
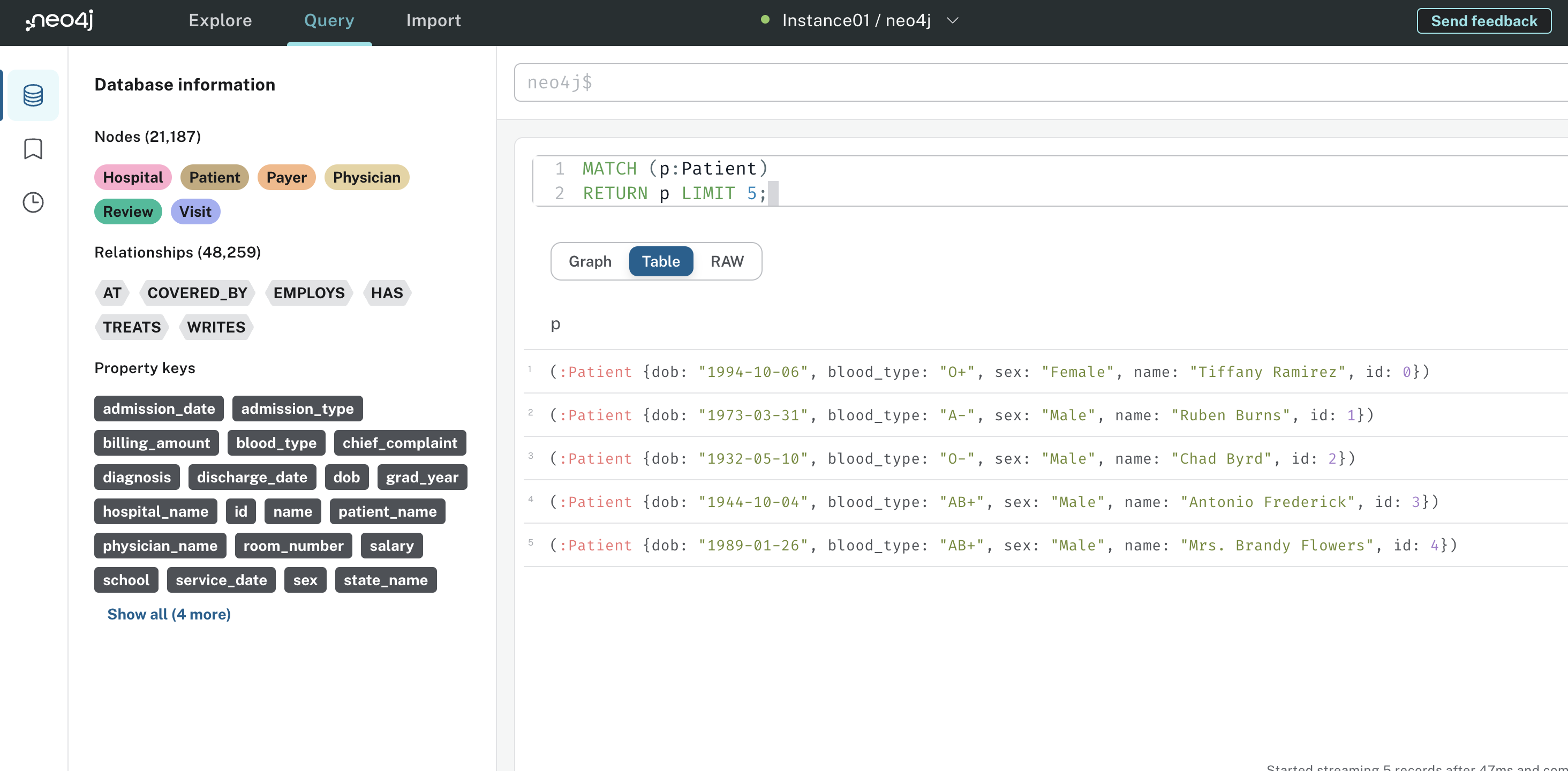
O Tabela mostra ao senhor os cinco Paciente Os senhores também podem explorar o gráfico e a exibição bruta se estiverem interessados. Se estiver interessado, o senhor também pode explorar o gráfico e a exibição bruta.
Embora a correspondência em um único nó seja simples, às vezes isso é tudo o que o senhor precisa para obter insights úteis. Por exemplo, se a parte interessada disse me dê um resumo da visita 56, a consulta a seguir lhe dá a resposta:
Essa consulta corresponde a Visit nós que têm um id de 56, especificado por WHERE v.id = 56. O senhor pode filtrar propriedades arbitrárias de nós e relações em WHERE cláusulas. Os resultados dessa consulta têm a seguinte aparência:
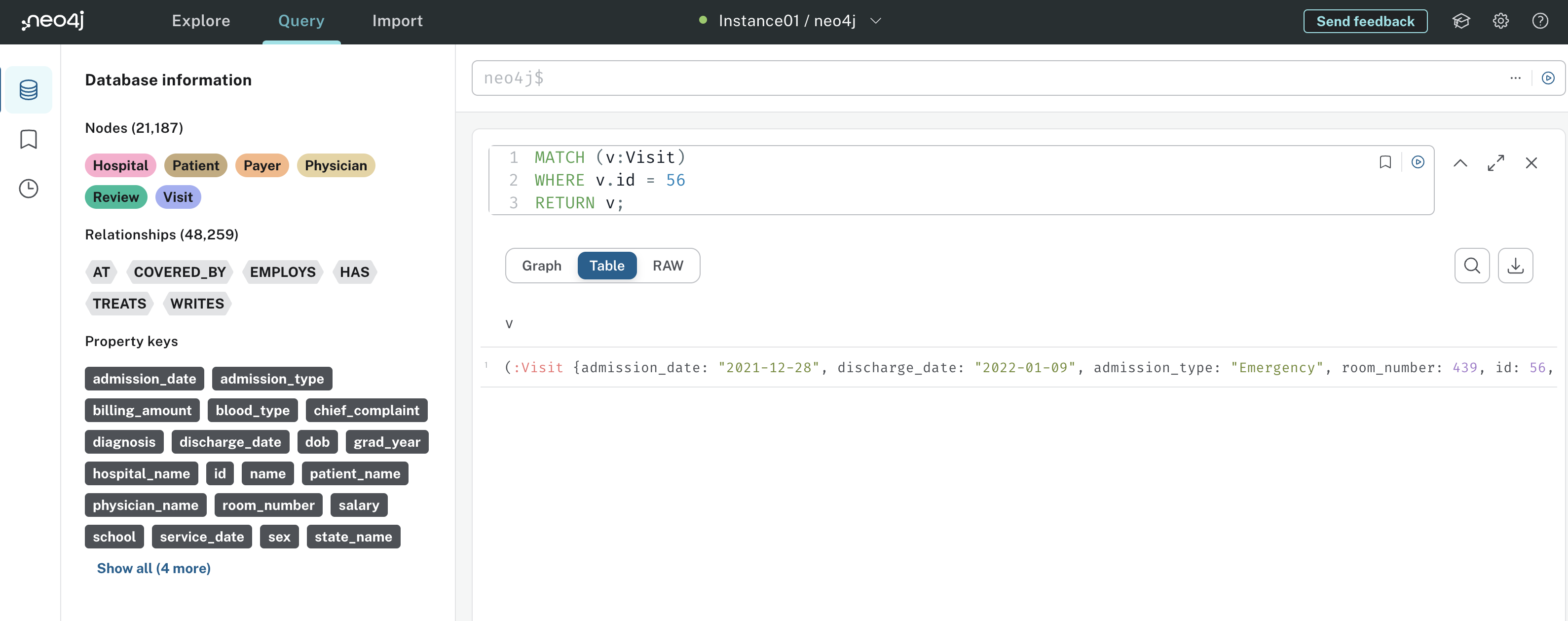
Na saída da consulta, o senhor pode ver o Visita de fato tem id 56. O senhor poderia então examinar todas as propriedades da visita para criar um resumo verbal da visita – é isso que a cadeia Cypher fará.
A correspondência de nós é excelente, mas o verdadeiro poder do Cypher vem de sua capacidade de correspondência de padrões de relacionamento. Isso lhe dá uma visão de relacionamentos sofisticados, explorando o poder dos bancos de dados de gráficos. Continuando com o Visite o senhor provavelmente quer saber qual Paciente o Visite pertence a. O senhor pode obter isso no HAS relacionamento:
Essa consulta do Cypher pesquisa o Patient que tenha um Visit com id 56. O senhor perceberá que a relação HAS está entre colchetes em vez de parênteses, e sua direcionalidade é indicada por uma seta. Se o senhor tentasse MATCH (p:Patient)<-[h:HAS]-(v:Visit), a consulta não retornaria nada porque a direção de HAS está incorreta.
Os resultados da consulta têm a seguinte aparência:
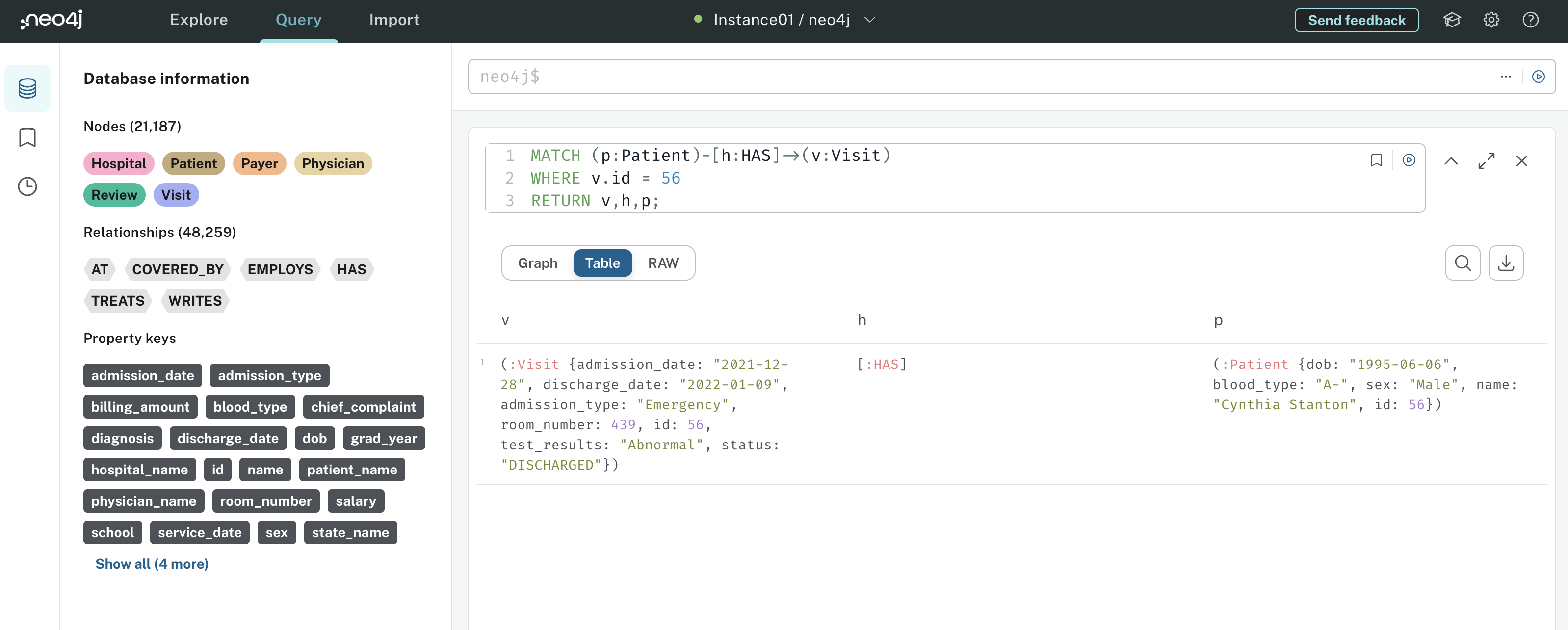
Observe que a saída inclui dados para o Visita, HAS e o senhor Paciente. Isso lhe dá mais informações do que se o senhor só fizesse a correspondência com Visite nós. Se o senhor quisesse ver quais médicos trataram o paciente durante o Visiteo senhor poderia adicionar a seguinte relação à consulta:
Esta declaração (p:Patient)-[h:HAS]->(v:Visit)<-[t:TREATS]-(ph:Physician) diz ao Neo4j para encontrar todos os padrões em que um Patient tem um Visit que é tratada por um Physician. Se o senhor quisesse combinar todos os relacionamentos que entram e saem do Visit o senhor poderia executar esta consulta:
Observe agora que a relação [r], não tem direção com relação a (v:Visit) ou (n). Em essência, essa declaração de correspondência procurará todos os relacionamentos que entram e saem do Visit 56, juntamente com os nós conectados a esses relacionamentos. Aqui estão os resultados:
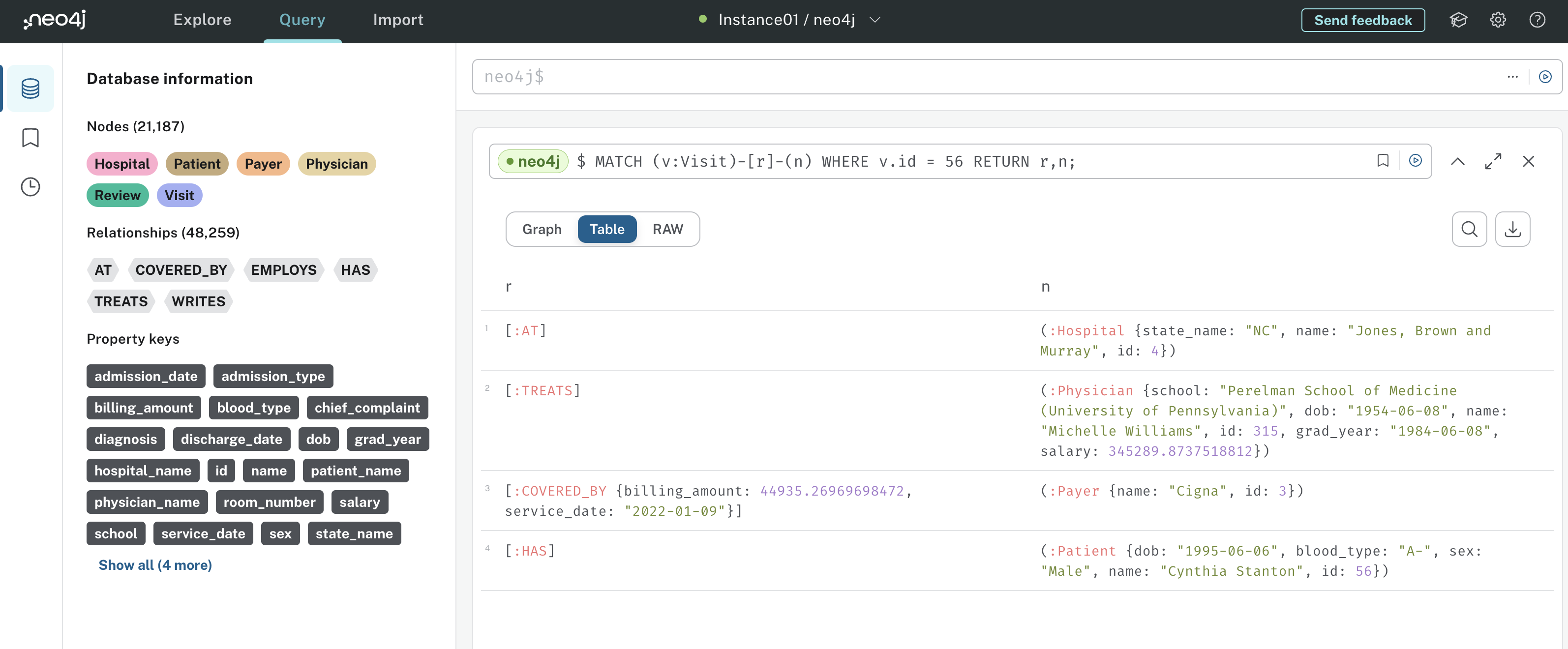
Isso lhe dá uma boa visão de todos os relacionamentos e nós associados ao Visite 56. Pense em como essa representação é poderosa. Em vez de realizar várias junções SQL, como teria de fazer em um banco de dados relacional, o senhor obtém todas as informações sobre como um Acesse está conectado a todo o sistema hospitalar com três linhas curtas de Cypher.
O senhor pode imaginar o quanto isso se tornaria mais poderoso à medida que mais nós e relacionamentos fossem adicionados ao banco de dados gráfico. Por exemplo, o senhor poderia registrar quais enfermeiros, farmácias, medicamentos ou cirurgias estão associados ao Visite. Cada relacionamento que o senhor adicionar precisará de outra junção no SQL, mas a consulta Cypher acima sobre Visite 56 permaneceria inalterado.
A última coisa que será abordada nesta seção é como realizar agregações no Cypher. Até agora, o senhor só consultou dados brutos de nós e relacionamentos, mas também pode calcular estatísticas agregadas no Cypher.
Suponha que o senhor queira responder à pergunta Qual é o número total de visitas e o valor total do faturamento das visitas cobertas pela Aetna no Texas? Aqui está a consulta do Cypher que responderia a essa pergunta:
Nessa consulta, o senhor primeiro combina todos os Visits que ocorrem em um Hospital e são cobertos por um Payer. Em seguida, o senhor filtra para Payers com um name propriedade de Aetna e Hospitals com um state_name de TX. Por fim, COUNT(*) conta o número de padrões correspondentes, e o SUM(c.billing_amount) fornece ao senhor o valor total do faturamento. O resultado tem a seguinte aparência:
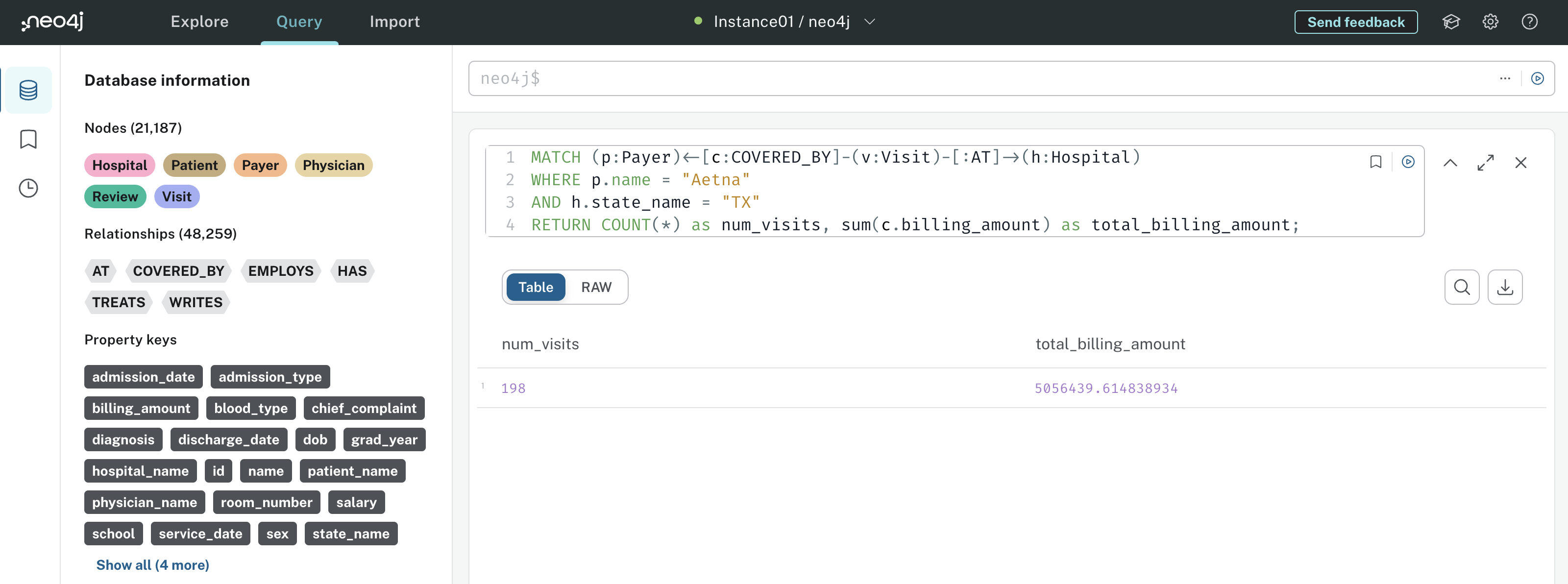
Os resultados informam ao senhor que havia 198 Visitas que correspondem a esse padrão, com um valor total de faturamento de cerca de US$ 5.056.439.
Agora o senhor tem uma sólida compreensão dos fundamentos do Cypher, bem como dos tipos de perguntas que pode responder. Em resumo, o Cypher é excelente para combinar relacionamentos complicados sem exigir uma consulta detalhada. Há muito mais que você pode fazer com o Neo4j e o Cypher, mas o conhecimento que obteve nesta seção é suficiente para começar a criar o chatbot, e é isso que você fará a seguir.
Etapa 4: Criar um Graph RAG Chatbot em LangChain
Depois de todo o trabalho preparatório de design e dados que fez até agora, o senhor finalmente está pronto para criar o seu chatbot! O senhor provavelmente perceberá que, com os dados do sistema hospitalar armazenados no Neo4j e o poder das abstrações da LangChain, a criação do seu chatbot não exige muito trabalho. Esse é um tema comum em projetos de IA e ML – a maior parte do trabalho está no design, na preparação dos dados e na implementação, e não na construção da IA propriamente dita.
Antes de começar, adicione um chatbot_api/ ao seu projeto com os seguintes arquivos e pastas:
./
│
├── chatbot_api/
│ │
│ ├── src/
│ │ │
│ │ ├── agents/
│ │ │ └── hospital_rag_agent.py
│ │ │
│ │ ├── chains/
│ │ │ ├── hospital_cypher_chain.py
│ │ │ └── hospital_review_chain.py
│ │ │
│ │ ├── tools/
│ │ │ └── wait_times.py
│ │
│ └── pyproject.toml
│
├── hospital_neo4j_etl/
│ │
│ ├── src/
│ │ ├── entrypoint.sh
│ │ └── hospital_bulk_csv_write.py
│ │
│ ├── Dockerfile
│ └── pyproject.toml
│
├── .env
└── docker-compose.yml
O senhor deverá adicionar mais algumas variáveis de ambiente ao seu .env também:
O senhor .env agora inclui variáveis que especificam qual LLM o senhor usará para diferentes componentes do seu chatbot. O senhor especificou esses modelos como variáveis de ambiente para que possa alternar facilmente entre diferentes modelos do OpenAI sem alterar nenhum código. No entanto, lembre-se de que cada LLM pode se beneficiar de uma estratégia de prompts exclusiva, portanto, talvez seja necessário modificar os prompts se o senhor planeja usar um conjunto diferente de LLMs.
O senhor já deve ter o hospital_neo4j_etl/ concluída, e o senhor já deve ter a pasta docker-compose.yml e .env são os mesmos de antes. Abrir chatbot_api/pyproject.toml e adicione as seguintes dependências:
O senhor certamente pode usar versões mais recentes dessas dependências, se estiverem disponíveis, mas lembre-se de quaisquer recursos que possam estar obsoletos. Abra um terminal, ative seu ambiente virtual, navegue até seu chatbot_api/ e instale as dependências da pasta do projeto pyproject.toml:
Quando tudo estiver instalado, o senhor estará pronto para criar a cadeia de revisões!
Criar uma cadeia de vetores do Neo4j
Em Etapa 1Na etapa 1, o senhor teve uma introdução prática à LangChain ao criar uma cadeia que responde a perguntas sobre experiências de pacientes usando suas avaliações. Nesta seção, o senhor criará uma cadeia semelhante, mas usará o Neo4j como índice vetorial.
Índices de pesquisa vetorial foram lançados como uma versão beta pública no Neo4j 5.11. Eles permitem que o senhor execute consultas semânticas diretamente no seu gráfico. Isso é muito conveniente para o seu chatbot porque o senhor pode armazenar os embeddings de revisão no mesmo local que os dados estruturados do sistema hospitalar.
No LangChain, o senhor pode usar Neo4jVector para criar embeddings de revisões e o retriever necessário para sua cadeia. Aqui está o código para criar a cadeia de revisões:
Nas linhas 1 a 11, o senhor importa as dependências necessárias para criar sua cadeia de revisões com o Neo4j. Na linha 13, o usuário carrega o nome do modelo de chat que usará para a cadeia de revisões e o armazena em HOSPITAL_QA_MODEL. As linhas 15 a 29 criam o índice do vetor no Neo4j. Veja a seguir o detalhamento de cada parâmetro:
embedding: O modelo usado para criar os embeddings – o senhor está usandoOpenAIEmeddings()neste exemplo.url,username, epassword: Suas credenciais de instância do Neo4j.index_name: O nome dado ao seu índice vetorial.node_label: O nó para o qual criar embeddings.text_node_properties: As propriedades do nó a serem incluídas na incorporação.embedding_node_property: O nome da propriedade do nó de incorporação.
Uma vez Neo4jVector.from_existing_graph() for executado, o senhor verá que cada Revisão no Neo4j tem um incorporação que é uma representação vetorial da propriedade nome_do_médico, nome_do_paciente, textoe nome_do_hospital propriedades. Isso permite que o senhor responda a perguntas como Quais hospitais tiveram avaliações positivas? Isso também permite que o LLM informe ao senhor quais pacientes e médicos escreveram avaliações que correspondem à sua pergunta.
As linhas 31 a 50 criam o modelo de prompt para sua cadeia de revisão da mesma forma que o senhor fez em Etapa 1.
Por fim, as linhas 52 a 57 criam sua cadeia de vetores de avaliações usando um recuperador de índice de vetores do Neo4j que retorna 12 embeddings de avaliações de uma pesquisa de similaridade. Ao definir chain_type para "stuff" em .from_chain_type(), o senhor está dizendo à cadeia para passar todas as 12 avaliações para o prompt. O senhor pode explorar outros tipos de cadeia em Documentação do LangChain sobre cadeias.
O senhor está pronto para experimentar sua nova cadeia de revisões. Navegue até o diretório raiz do seu projeto, inicie um interpretador Python e execute os seguintes comandos:
Nesse bloco, o senhor importa dotenv e carrega as variáveis de ambiente do .env. Em seguida, o senhor importa reviews_vector_chain do hospital_review_chain e invoque-o com uma pergunta sobre a eficiência do hospital. A resposta da sua cadeia pode não ser idêntica a essa, mas o LLM deve retornar um bom resumo detalhado, como o senhor disse.
Neste exemplo, observe como os nomes específicos de pacientes e hospitais são mencionados na resposta. Isso acontece porque o senhor incorporou os nomes do hospital e do paciente junto com o texto da revisão, para que o LLM possa usar essas informações para responder às perguntas.
Observação: Antes de prosseguir, o senhor deve brincar com o reviews_vector_chain para ver como ele responde a diferentes consultas. As respostas parecem corretas? Como o senhor poderia avaliar a qualidade do reviews_vector_chain? O senhor não aprenderá a avaliar sistemas RAG neste tutorial, mas pode dar uma olhada no seguinte exemplo abrangente em Python com MLFlow para ter uma ideia de como isso é feito.
Em seguida, o senhor criará a cadeia de geração Cypher que usará para responder a consultas sobre dados estruturados do sistema hospitalar.
Criar uma cadeia Cypher no Neo4j
Como o senhor viu em Passo 2Na etapa 3, a cadeia Cypher do Neo4j aceitará a consulta de linguagem natural do usuário, converterá a consulta de linguagem natural em uma consulta Cypher, executará a consulta Cypher no Neo4j e usará os resultados da consulta Cypher para responder à consulta do usuário. O senhor aproveitará o recurso LangChain’s GraphCypherQAChain do LangChain para isso.
Nota: Sempre que permitir que os usuários consultem um banco de dados, como fará com a cadeia Cypher, é preciso garantir que eles tenham apenas as permissões necessárias. As credenciais do Neo4j que o senhor está usando neste projeto permitem que os usuários leiam, gravem, atualizem e excluam dados do seu banco de dados.
Se o senhor estivesse criando esse aplicativo para um projeto do mundo real, seria bom criar credenciais que restringissem as permissões do usuário somente à leitura, evitando que ele escrevesse ou excluísse dados valiosos.
Usar LLMs para gerar consultas Cypher precisas pode ser um desafio, especialmente se o senhor tiver um gráfico complicado. Por isso, é necessária muita engenharia de prompt para mostrar a estrutura do gráfico e os casos de uso da consulta ao LLM. Ajuste fino um LLM para gerar consultas também é uma opção, mas isso requer dados rotulados e com curadoria manual.
Para começar a criar sua cadeia de geração Cypher, importe as dependências e instancie um Neo4jGraph:
O Neo4jGraph é um wrapper LangChain que permite que os LLMs executem consultas em sua instância do Neo4j. O usuário instancia o graph usando suas credenciais do Neo4j e chama o graph.refresh_schema() para sincronizar quaisquer alterações recentes em sua instância.
O próximo e mais importante componente da cadeia de geração do Cypher é o modelo de prompt. Veja como ele se parece:
Leia o conteúdo de cypher_generation_template com atenção. Observe como o senhor está fornecendo ao LLM instruções muito específicas sobre o que ele deve ou não fazer ao gerar consultas Cypher. Mais importante ainda, o senhor está mostrando ao LLM a estrutura do seu gráfico com o comando schema alguns exemplos de consultas e os valores categóricos de algumas propriedades de nós.
Todos os detalhes que o senhor fornece no seu modelo de prompt aumentam a chance de o LLM gerar uma consulta Cypher correta para uma determinada pergunta. Se o senhor estiver curioso para saber se todos esses detalhes são necessários, tente criar seu próprio modelo de prompt com o mínimo de detalhes possível. Em seguida, execute as perguntas por meio de sua cadeia Cypher e veja se ela gera corretamente as consultas Cypher.
A partir daí, é possível atualizar iterativamente o modelo de prompt para corrigir as consultas que o LLM tem dificuldade para gerar, mas certifique-se de que também esteja ciente do número de tokens de entrada que está usando. Assim como acontece com a cadeia de revisão, o senhor desejará ter um sistema sólido para avaliar os modelos de prompt e a correção das consultas Cypher geradas pela cadeia. Entretanto, como verá, o modelo que o senhor tem acima é um ótimo ponto de partida.
Observação: O modelo de prompt acima fornece ao LLM quatro exemplos de consultas Cypher válidas para seu gráfico. Dar ao LLM alguns exemplos e depois pedir que ele execute uma tarefa é conhecido como prompting de poucas tentativase é uma técnica simples, porém poderosa, para melhorar a precisão da geração.
No entanto, o prompting de poucos disparos pode não ser suficiente para a geração de consultas Cypher, especialmente se o senhor tiver um gráfico complicado. Uma maneira de melhorar isso é criar um banco de dados vetorial que incorpore exemplos de perguntas/consultas de usuários e armazene as consultas Cypher correspondentes como metadados.
Quando um usuário faz uma pergunta, o senhor injeta consultas Cypher de perguntas semanticamente semelhantes no prompt, fornecendo ao LLM os exemplos mais relevantes necessários para responder à pergunta atual.
Em seguida, o senhor define o modelo de prompt para o componente pergunta-resposta da sua cadeia. Esse modelo informa ao LLM para usar os resultados da consulta Cypher para gerar uma resposta bem formatada à consulta do usuário:
Esse modelo requer muito menos detalhes do que o modelo de geração do Cypher e o usuário só precisará modificá-lo se quiser que o LLM responda de forma diferente ou se perceber que ele não está usando os resultados da consulta da forma desejada. A última etapa na criação da cadeia Cypher é instanciar um GraphCypherQAChain :
Aqui está um detalhamento dos parâmetros usados no GraphCypherQAChain.from_llm():
cypher_llm: O LLM usado para gerar consultas Cypher.qa_llm: O LLM usado para gerar uma resposta a partir dos resultados da consulta Cypher.graph: ONeo4jGraphque se conecta à sua instância do Neo4j.verbose: Se as etapas intermediárias executadas pela cadeia devem ser impressas.qa_prompt: O modelo de prompt para responder a perguntas/consultas.cypher_prompt: O modelo de prompt para gerar consultas Cypher.validate_cypher: Se verdadeiro, a consulta Cypher será inspecionada quanto a erros e corrigida antes da execução. Observe que isso não garante que a consulta Cypher será válida. Em vez disso, ele corrige erros simples de sintaxe que são facilmente detectáveis usando o expressões regulares.top_k: O número de resultados de consulta a serem incluídos noqa_prompt.
Sua cadeia de geração Cypher do sistema hospitalar está pronta para ser usada! Ela funciona da mesma forma que sua cadeia de revisões. Navegue até o diretório do projeto e inicie uma nova sessão do interpretador Python e, em seguida, experimente:
Após carregar as variáveis de ambiente, importar o hospital_cypher_chaine invocá-lo com uma pergunta, o senhor pode ver as etapas da cadeia para responder à pergunta. Reserve um segundo para apreciar algumas realizações que sua cadeia fez ao gerar a consulta Cypher:
- O LLM de geração do Cypher entendeu a relação entre visitas e hospitais a partir do esquema gráfico fornecido.
- Embora o senhor tenha perguntado sobre Carolina do Norte, o LLM sabia, pelo prompt, que deveria usar a abreviação do estado NC.
- O LLM sabia disso admission_type têm apenas a primeira letra em maiúscula, enquanto as propriedades status as propriedades estão todas em letras maiúsculas.
- O LLM da geração de QA sabia, pelo seu aviso, que os resultados da consulta estavam em unidades de dias.
O senhor pode fazer experiências com todos os tipos de consultas sobre o sistema hospitalar. Por exemplo, aqui está uma pergunta relativamente desafiadora para ser convertida em Cypher:
Para responder à pergunta Qual estado teve o maior aumento percentual em visitas do Medicaid de 2022 a 2023?o LLM teve de gerar uma consulta Cypher bastante detalhada, envolvendo vários nós, relacionamentos e filtros. Mesmo assim, ele conseguiu chegar à resposta correta.
O último recurso de que o seu chatbot precisa é responder a perguntas sobre tempos de espera, e é isso que o senhor abordará a seguir.
Criar funções de tempo de espera
O último recurso de que o seu chatbot precisa é responder a perguntas sobre os tempos de espera do hospital. Como discutido anteriormente, a sua organização não armazena dados sobre o tempo de espera em lugar nenhum, portanto, o seu chatbot terá de buscá-los em uma fonte externa. O senhor escreverá duas funções para isso – uma que simula encontrar o tempo de espera atual em um hospital e outra que encontra o hospital com o menor tempo de espera.
Observação: O objetivo de criar funções de tempo de espera é mostrar ao senhor que os agentes LangChain podem executar código Python arbitrário, não apenas cadeias ou outros métodos LangChain. Esse recurso é extremamente valioso porque significa que, em teoria, o senhor poderia criar um agente para fazer praticamente qualquer coisa que possa ser expressa em código.
Comece definindo funções para obter os tempos de espera atuais em um hospital:
A primeira função que o senhor define é _get_current_hospitals() que retorna uma lista de nomes de hospitais do seu banco de dados Neo4j. Em seguida, _get_current_wait_time_minutes() recebe um nome de hospital como entrada. Se o nome do hospital for inválido, _get_current_wait_time_minutes() retorna -1. Se o nome do hospital for válido, _get_current_wait_time_minutes() retorna um número inteiro aleatório entre 0 e 600, simulando um tempo de espera em minutos.
Em seguida, o senhor define get_current_wait_times() que é um invólucro em torno do _get_current_wait_time_minutes() que retorna o tempo de espera formatado como uma string.
O senhor pode usar o _get_current_wait_time_minutes() para definir uma segunda função que encontre o hospital com o menor tempo de espera:
Aqui, o senhor define get_most_available_hospital() que chama o _get_current_wait_time_minutes() em cada hospital e retorna o hospital com o menor tempo de espera. Observe como o get_most_available_hospital() tem um entrada descartável _. Isso será exigido mais tarde pelo seu agente porque ele foi projetado para passar entradas para funções.
Veja como o senhor usa o get_current_wait_times() e get_most_available_hospital():
Depois de carregar as variáveis de ambiente, o senhor chama get_current_wait_times("Wallace-Hamilton") que retorna o tempo de espera atual em minutos para o Wallace-Hamilton hospital. Quando o senhor tenta get_current_wait_times("fake hospital"), o senhor recebe uma mensagem dizendo hospital falso não existe no banco de dados.
Por fim, get_most_available_hospital() retorna um dicionário que armazena o tempo de espera do hospital com o menor tempo de espera em minutos. Em seguida, o senhor criará um agente que usa essas funções, juntamente com o Cypher e a cadeia de revisão, para responder a perguntas arbitrárias sobre o sistema hospitalar.
Criar o agente do chatbot
Se o senhor chegou até aqui, dê um tapinha nas suas costas. O senhor cobriu uma grande quantidade de informações e finalmente está pronto para juntar tudo e montar o agente que servirá como seu chatbot. Dependendo da consulta que o senhor lhe der, o agente precisará decidir entre as funções Cypher chain, reviews chain e wait times.
Comece carregando as dependências do agente, lendo o nome do modelo do agente a partir de uma variável de ambiente e carregando um modelo de prompt do LangChain Hub:
Observe como o senhor está importando reviews_vector_chain, hospital_cypher_chain, get_current_wait_times(), e get_most_available_hospital(). Seu agente os usará diretamente como ferramentas. HOSPITAL_AGENT_MODEL é o LLM que atuará como o cérebro do seu agente, decidindo quais ferramentas chamar e quais entradas passar a elas.
Em vez de definir seu próprio prompt para o agente, o que certamente pode ser feito, o senhor carrega um prompt predefinido do LangChain Hub. O LangChain Hub permite que o senhor carregue, navegue, extraia, teste e gerencie prompts. Nesse caso, o prompt padrão para agentes de função OpenAI funciona muito bem.
Em seguida, o senhor define uma lista de ferramentas que seu agente pode usar:
Seu agente tem quatro ferramentas disponíveis: Experiências, Gráfico, Esperae Disponibilidade. Os Experiências e Gráfico chamada de ferramentas .invoke() de suas respectivas cadeias, enquanto o Espera e Disponibilidade chamar as funções de tempo de espera que o senhor definiu. Observe que muitas das descrições de ferramentas têm prompts de poucos segundos, informando ao agente quando ele deve usar a ferramenta e fornecendo um exemplo de quais entradas devem ser passadas.
Assim como acontece com as cadeias, uma boa engenharia de prompts é fundamental para o sucesso do seu agente. O senhor precisa descrever claramente cada ferramenta e como usá-la para que seu agente não se confunda com uma consulta.
A última etapa é instanciar o agente:
Primeiro, o senhor inicializa um ChatOpenAI usando HOSPITAL_AGENT_MODEL como o LLM. Em seguida, o senhor cria um agente de funções OpenAI com create_openai_functions_agent(). Isso cria um agente que foi projetado pela OpenAI para passar entradas para funções. Ele faz isso retornando objetos JSON que armazenam entradas de funções e seus valores correspondentes.
Para criar o tempo de execução do agente, o usuário passa o agente e as ferramentas para AgentExecutor. Configurações return_intermediate_steps e verbose para true permite que o senhor veja o processo de pensamento do agente e as ferramentas que ele utiliza.
Com isso, o senhor concluiu a criação do agente do sistema hospitalar. Para experimentá-lo, o senhor terá de navegar até o diretório chatbot_api/src/ e iniciar uma nova sessão REPL a partir daí.
Observação: Isso é necessário porque o senhor configura importações relativas em hospital_rag_agent.py que serão executadas posteriormente em um contêiner do Docker. Por enquanto, isso significa que o senhor terá que iniciar o interpretador Python somente depois de navegar para chatbot_api/src/ para que as importações funcionem.
Agora o senhor pode testar o agente do sistema do hospital na linha de comando:
Depois de carregar as variáveis de ambiente, o senhor pergunta ao agente sobre os tempos de espera. O senhor pode ver exatamente o que ele está fazendo em resposta a cada uma de suas consultas. Por exemplo, quando o senhor pergunta ao “Qual é o tempo de espera em Wallace-Hamilton?”, ele invoca o Aguarde ferramenta e passes Wallace-Hamilton como entrada. Isso significa que o agente está chamando get_current_wait_times("Wallace-Hamilton"), observando o valor de retorno e usando o valor de retorno para responder à pergunta do senhor.
Para ver todos os recursos dos agentes, o senhor pode fazer perguntas sobre as experiências dos pacientes que exigem avaliações dos pacientes para serem respondidas:
Observe aqui como o senhor nunca menciona explicitamente avaliações ou experiências em sua pergunta. O agente sabe, com base na descrição da ferramenta, que precisa invocar o Experiências. Por fim, o senhor pode fazer uma pergunta ao agente que exija uma consulta Cypher para ser respondida:
Seu agente tem uma capacidade notável de saber quais ferramentas usar e quais entradas passar com base na sua consulta. Esse é o seu chatbot em pleno funcionamento. Ele tem o potencial de responder a todas as perguntas que as partes interessadas possam fazer com base nos requisitos fornecidos, e parece estar fazendo um ótimo trabalho até agora.
À medida que o senhor faz mais perguntas ao seu chatbot, é quase certo que encontrará situações em que ele chama a ferramenta errada ou gera uma resposta incorreta. Embora modificar os prompts possa ajudar a solucionar respostas incorretas, às vezes o senhor pode modificar a consulta de entrada para ajudar o chatbot. Dê uma olhada neste exemplo:
Nesse exemplo, o senhor pede ao agente que lhe mostre as avaliações escritas pelo paciente 7674. Seu agente invoca Experiences e não encontra a resposta que o senhor está procurando. Embora possa ser possível encontrar a resposta usando a pesquisa vetorial semântica, o senhor pode obter uma resposta exata gerando uma consulta Cypher para procurar revisões correspondentes ao ID de paciente 7674. Para ajudar seu agente a entender isso, o senhor pode adicionar mais detalhes à sua consulta:
Aqui, o senhor diz explicitamente ao seu agente que deseja consultar o banco de dados de gráficos, que invoca corretamente Graph para encontrar a revisão correspondente ao ID do paciente 7674. Fornecer mais detalhes em suas consultas como essa é uma maneira simples, mas eficaz, de orientar o agente quando ele está claramente invocando as ferramentas erradas.
Assim como acontece com as revisões e a cadeia Cypher, antes de apresentar isso às partes interessadas, o senhor deve criar uma estrutura para avaliar o agente. A principal funcionalidade que o senhor deseja avaliar é a capacidade do agente de chamar as ferramentas corretas com as entradas corretas e sua capacidade de entender e interpretar as saídas das ferramentas que ele chama.
Na etapa final, o senhor aprenderá a implantar seu agente de sistema hospitalar com FastAPI e Streamlit. Isso tornará seu agente acessível a qualquer pessoa que chame o endpoint da API ou interaja com a UI do Streamlit.
Etapa 5: implantar o agente LangChain
Finalmente, o senhor tem um agente LangChain em funcionamento que serve como chatbot do sistema do hospital. A última coisa que o senhor precisa fazer é colocar o chatbot na frente das partes interessadas. Para isso, o senhor implantará o chatbot como um ponto de extremidade FastAPI e criará uma interface de usuário Streamlit para interagir com o ponto de extremidade.
Antes de começar, crie duas novas pastas chamadas chatbot_frontend/ e tests/ no diretório raiz do seu projeto. O senhor também precisará adicionar alguns arquivos e pastas adicionais ao chatbot_api/:
./
│
├── chatbot_api/
│ │
│ ├── src/
│ │ │
│ │ ├── agents/
│ │ │ └── hospital_rag_agent.py
│ │ │
│ │ ├── chains/
│ │ │ ├── hospital_cypher_chain.py
│ │ │ └── hospital_review_chain.py
│ │ │
│ │ ├── models/
│ │ │ └── hospital_rag_query.py
│ │ │
│ │ ├── tools/
│ │ │ └── wait_times.py
│ │ │
│ │ ├── utils/
│ │ │ └── async_utils.py
│ │ │
│ │ ├── entrypoint.sh
│ │ └── main.py
│ │
│ ├── Dockerfile
│ └── pyproject.toml
│
├── chatbot_frontend/
│ │
│ ├── src/
│ │ ├── entrypoint.sh
│ │ └── main.py
│ │
│ ├── Dockerfile
│ └── pyproject.toml
│
├── hospital_neo4j_etl/
│ │
│ ├── src/
│ │ ├── entrypoint.sh
│ │ └── hospital_bulk_csv_write.py
│ │
│ ├── Dockerfile
│ └── pyproject.toml
│
├── tests/
│ ├── async_agent_requests.py
│ └── sync_agent_requests.py
│
├── .env
└── docker-compose.yml
O senhor precisa dos novos arquivos em chatbot_api para criar seu aplicativo FastAPI, e tests/ tem dois scripts para demonstrar o poder de fazer solicitações assíncronas ao seu agente. Por fim, chatbot_frontend/ tem o código da interface do usuário do Streamlit que fará a interface com o seu chatbot. O senhor começará criando um aplicativo FastAPI para atender ao seu agente.
Atender o agente com FastAPI
FastAPI é uma estrutura da Web moderna e de alto desempenho para criar APIs com Python com base em dicas de tipo padrão. Ele vem com muitos recursos excelentes, incluindo velocidade de desenvolvimento, velocidade de tempo de execução e excelente suporte da comunidade, o que o torna uma ótima opção para atender ao seu agente de chatbot.
O senhor atenderá ao seu agente por meio de um POST portanto, a primeira etapa é definir quais dados o senhor espera obter no corpo da solicitação e quais dados a solicitação retorna. A FastAPI faz isso com Pydantic:
Nesse script, o senhor define os modelos Pydantic HospitalQueryInput e HospitalQueryOutput. HospitalQueryInput é usado para verificar se o corpo da solicitação POST inclui um text que representa a consulta à qual seu chatbot responde. HospitalQueryOutput verifica se o corpo da resposta enviada de volta ao usuário inclui input, output, e intermediate_step campos.
Um ótimo recurso da FastAPI é o assíncrono recursos de atendimento. Como o seu agente chama os modelos da OpenAI hospedados em um servidor externo, sempre haverá latência enquanto o agente aguarda uma resposta. Essa é uma oportunidade perfeita para o senhor usar a programação assíncrona.
Em vez de esperar que a OpenAI responda a cada uma das solicitações do seu agente, o senhor pode fazer com que o agente faça várias solicitações seguidas e armazene as respostas à medida que forem recebidas. Isso economizará muito tempo se o senhor tiver várias consultas às quais precisa que o agente responda.
Conforme discutido anteriormente, às vezes pode haver problemas intermitentes de conexão com o Neo4j, que geralmente são resolvidos com o estabelecimento de uma nova conexão. Por isso, o senhor deve implementar uma lógica de repetição que funcione para funções assíncronas:
Não se preocupe com os detalhes do @async_retry. Tudo o que o senhor precisa saber é que ele tentará novamente uma função assíncrona se ela falhar. O senhor verá onde isso é usado a seguir.
A lógica de condução da API do seu chatbot está em chatbot_api/src/main.py:
O senhor importa FastAPI, seu executor de agente, os modelos Pydantic que o senhor criou para a solicitação POST e @async_retry. Em seguida, o senhor instancia um FastAPI e define invoke_agent_with_retry()uma função que executa seu agente de forma assíncrona. A função @async_retry acima invoke_agent_with_retry() garante que a função será tentada novamente dez vezes com um atraso de um segundo antes de falhar.
Por fim, o senhor define query_hospital_agent() que atende a solicitações POST para seu agente em /hospital-rag-agent. Essa função extrai o text do corpo da solicitação, passa-o para o agente e retorna a resposta do agente para o usuário.
O senhor atenderá a essa API com o Docker e desejará definir o seguinte arquivo de ponto de entrada para ser executado dentro do contêiner:
O comando uvicorn main:app --host 0.0.0.0 --port 8000 executa o aplicativo FastAPI na porta 8000 do seu computador. O comando Dockerfile para seu aplicativo FastAPI tem a seguinte aparência:
Este Dockerfile diz ao seu contêiner para usar o python:3.11-slim distribuição, copie o conteúdo de chatbot_api/src/ para o arquivo /app no diretório do contêiner, instale as dependências do pyproject.tomle execute entrypoint.sh.
A última coisa que o senhor precisará fazer é atualizar o docker-compose.yml para incluir seu contêiner FastAPI:
Aqui o senhor adiciona o chatbot_api que é derivado do serviço Dockerfile no ./chatbot_api. Depende de hospital_neo4j_etl e será executado na porta 8000.
Para executar a API, juntamente com o ETL que o senhor criou anteriormente, abra um terminal e execute:
Se tudo for executado com êxito, o senhor verá uma tela semelhante à seguinte em http://localhost:8000/docs#/:
O senhor pode usar a página de documentação para testar o hospital-rag-agent mas o senhor não poderá fazer solicitações assíncronas aqui. Para ver como seu endpoint lida com solicitações assíncronas, o senhor pode testá-lo com uma biblioteca como httpx.
Nota: O senhor precisa instalar o httpx em seu ambiente virtual antes de executar os testes abaixo.
Para ver quanto tempo as solicitações assíncronas economizam para o senhor, comece estabelecendo um benchmark usando solicitações síncronas. Crie o seguinte script:
Nesse script, o senhor importa requests e time, defina o URL do seu chatbot, crie uma lista de perguntas e registre o tempo necessário para obter uma resposta a todas as perguntas da lista. Se o senhor abrir um terminal e executar sync_agent_requests.py, o senhor verá quanto tempo leva para responder a todas as 14 perguntas:
Os resultados podem ser ligeiramente diferentes, dependendo da velocidade da sua Internet e da disponibilidade do modelo de bate-papo, mas o senhor pode ver que esse script levou cerca de 68 segundos para ser executado. A seguir, o senhor obterá respostas para as mesmas perguntas de forma assíncrona:
Em async_agent_requests.pyo senhor faz a mesma solicitação que fez em sync_agent_requests.py, só que agora o senhor usa httpx para fazer as solicitações de forma assíncrona. Aqui estão os resultados:
Novamente, o tempo exato que isso leva para ser executado pode variar para o senhor, mas é possível ver que fazer 14 solicitações de forma assíncrona foi aproximadamente quatro vezes mais rápido. A implementação do agente de forma assíncrona permite que o senhor dimensione para um volume alto de solicitações sem precisar aumentar as demandas de infraestrutura. Embora sempre haja exceções, atender aos endpoints REST de forma assíncrona geralmente é uma boa ideia quando seu código faz solicitações vinculadas à rede.
Com esse endpoint FastAPI funcionando, o senhor tornou seu agente acessível a qualquer pessoa que possa acessar o endpoint. Isso é ótimo para integrar seu agente em UIs de chatbot, que é o que o senhor fará a seguir com o Streamlit.
Criar uma interface de usuário de chat com o Streamlit
Suas partes interessadas precisam de uma maneira de interagir com seu agente sem fazer solicitações manuais de API. Para acomodar isso, o senhor criará uma Streamlit que atua como uma interface entre as partes interessadas e a API. Aqui estão as dependências da interface do usuário do Streamlit:
O código de condução do seu aplicativo Streamlit está em chatbot_frontend/src/main.py:
O aprendizado do Streamlit não é o foco deste tutorial, portanto, o senhor não terá uma descrição detalhada desse código. Entretanto, aqui está uma visão geral de alto nível do que essa UI faz:
- Todo o histórico de bate-papo é armazenado e exibido sempre que o usuário faz uma nova consulta.
- A interface do usuário recebe a entrada do usuário e faz uma solicitação POST síncrona para o ponto de extremidade do agente.
- A resposta mais recente do agente é exibida na parte inferior do chat e anexada ao histórico do chat.
- Uma explicação de como o agente gerou a resposta que forneceu ao usuário. Isso é ótimo para fins de auditoria, pois o senhor pode ver se o agente chamou a ferramenta certa e pode verificar se a ferramenta funcionou corretamente.
Como o senhor fez, criará um arquivo de ponto de entrada para executar a UI:
E, por fim, o arquivo Docker para criar uma imagem para a UI:
Este Dockerfile é idêntico aos anteriores que o senhor criou. Com isso, o senhor está pronto para executar todo o seu aplicativo de chatbot de ponta a ponta.
Orquestrar o projeto com o Docker Compose
Neste ponto, o senhor já escreveu todo o código necessário para executar o seu chatbot. A última etapa é criar e executar seu projeto com o docker-compose. Antes de fazer isso, certifique-se de que todos os arquivos e pastas a seguir estejam no diretório do projeto:
./
│
├── chatbot_api/
│ │
│ │
│ ├── src/
│ │ │
│ │ ├── agents/
│ │ │ └── hospital_rag_agent.py
│ │ │
│ │ ├── chains/
│ │ │ │
│ │ │ ├── hospital_cypher_chain.py
│ │ │ └── hospital_review_chain.py
│ │ │
│ │ ├── models/
│ │ │ └── hospital_rag_query.py
│ │ │
│ │ ├── tools/
│ │ │ └── wait_times.py
│ │ │
│ │ ├── utils/
│ │ │ └── async_utils.py
│ │ │
│ │ ├── entrypoint.sh
│ │ └── main.py
│ │
│ ├── Dockerfile
│ └── pyproject.toml
│
├── chatbot_frontend/
│ │
│ ├── src/
│ │ ├── entrypoint.sh
│ │ └── main.py
│ │
│ ├── Dockerfile
│ └── pyproject.toml
│
├── hospital_neo4j_etl/
│ │
│ ├── src/
│ │ ├── entrypoint.sh
│ │ └── hospital_bulk_csv_write.py
│ │
│ ├── Dockerfile
│ └── pyproject.toml
│
├── tests/
│ ├── async_agent_requests.py
│ └── sync_agent_requests.py
│
├── .env
└── docker-compose.yml
O senhor .env deve ter as seguintes variáveis de ambiente. A maioria delas foi criada anteriormente neste tutorial, mas você também precisará adicionar uma nova variável para CHATBOT_URL para que o aplicativo Streamlit possa encontrar sua API:
Para completar sua docker-compose.yml o senhor precisará adicionar um arquivo chatbot_frontend serviço. Sua versão final docker-compose.yml deve ter a seguinte aparência:
Por fim, abra um terminal e execute:
Depois que tudo for compilado e executado, o senhor poderá acessar a interface do usuário em http://localhost:8501/ e começar a conversar com seu chatbot:
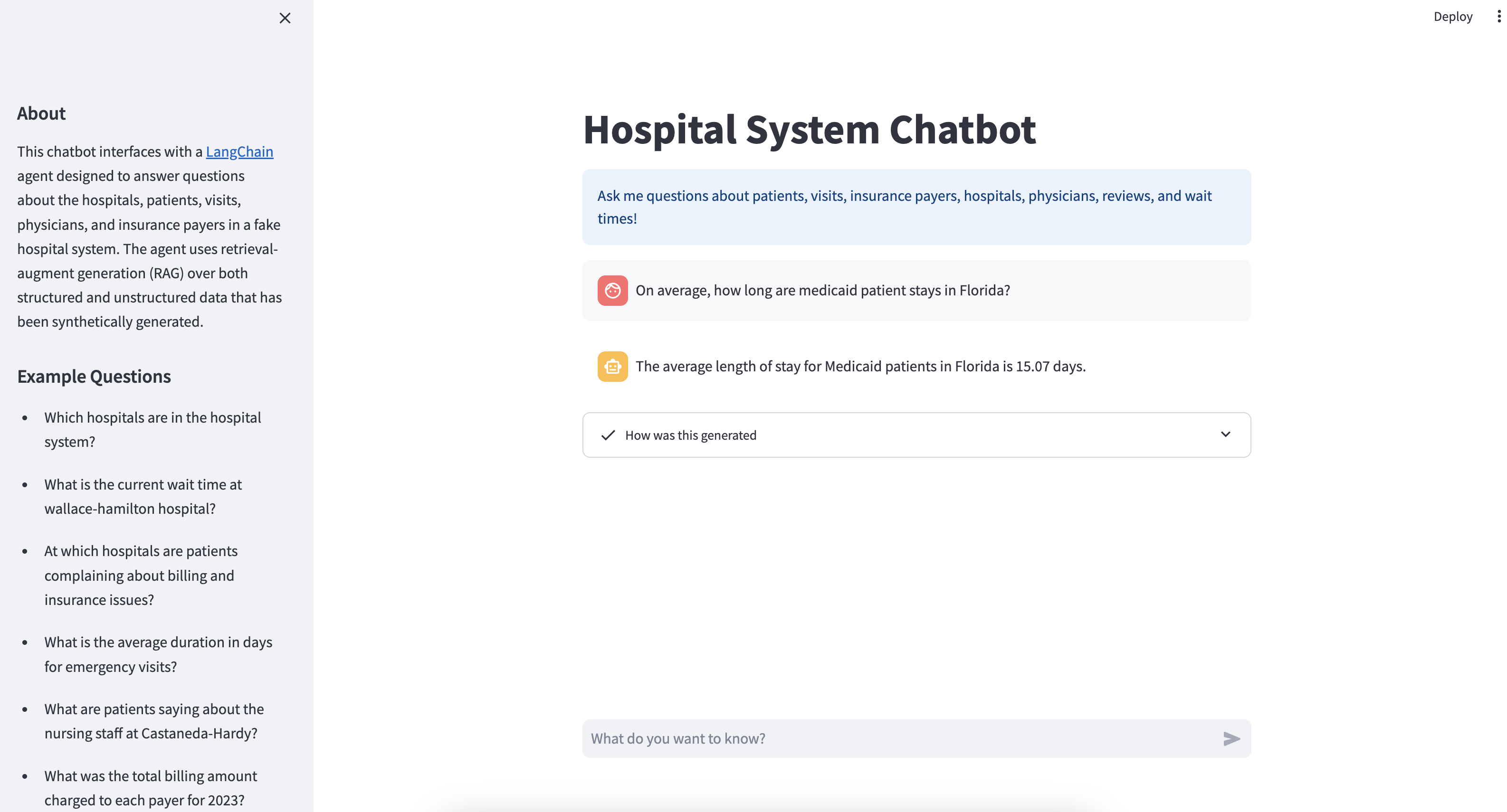
O senhor criou um chatbot de sistema hospitalar totalmente funcional de ponta a ponta. Reserve algum tempo para fazer perguntas a ele, veja os tipos de perguntas que ele é bom em responder, descubra onde ele falha e pense em como o senhor pode melhorá-lo com melhores estímulos ou dados. O senhor pode começar certificando-se de que as perguntas de exemplo na barra lateral sejam respondidas com sucesso.
Conclusão
Parabéns por ter concluído este tutorial detalhado!
O senhor projetou, criou e serviu com sucesso um chatbot RAG LangChain que responde a perguntas sobre um sistema hospitalar falso. Certamente, há muitas maneiras de aprimorar o chatbot criado neste tutorial, mas agora você tem uma sólida compreensão de como integrar o LangChain aos seus próprios dados, o que lhe dá liberdade criativa para criar todos os tipos de chatbots personalizados.
Neste tutorial, o senhor aprendeu a:
- Usar LangChain para criar um chatbots.
- Crie um chatbot para um sistema hospitalar falso, alinhando-se com o requisitos de negócios e aproveitamento dos dados disponíveis.
- Considere a implementação do bancos de dados de grafos em seu projeto de chatbot.
- Configure um Neo4j AuraDB para seu projeto.
- Desenvolva um RAG chatbot capaz de buscar ambos estruturado e não estruturado dados do Neo4j.
- Implante seu chatbot usando FastAPI e Streamlit.
O código-fonte e os dados completos desse projeto podem ser encontrados nos materiais de apoio, que podem ser baixados usando o link abaixo: